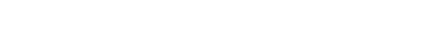
はじめに
この記事では機械学習や統計をやったことはないけどAIを使ってみたい、といった方に向けた記事になっています。
機械学習にはプログラムや統計など知識の壁が大きく、またモデルの差育成に対する時間の壁も大きいかと思います。
今回利用するAutoMLツール「ナレコムAI」を利用することで5分ほどで簡単にモデルを作成でき、モデルの評価についても作成されるレポートを読むことでMLの知識がなくともモデルの特性やよいモデルにするためのアプローチ内容を把握することができます。「データはあるけど、活用できるかわからない」「AIについて興味があるけど敷居が高そう」と考えている方が、少しでも前進するきっかけになれたら嬉しいです!
なぜ高い精度のモデルが作成できるのか
本来であればパラメータの選定やアルゴリズムについての学習、選定など知識や時間がかかってしまいます。
ナレコムAIでは事前に用意されたアルゴリズムやパラメータの組み合わせ数十種類をすべて試し、その中で最も良いモデルを提供しています。
そのため、パラメータの探索漏れなどがなく、精度の高いモデルの作成、提供を行うことができるのです。
さらに、データの登録からモデルの作成、モデルの解釈についてのレポートを作成するため、モデルの精度向上までを含めノーコードで行うことができます。
 |
データを見てみる
ではまず今回のデータについてみてみたいと思います。
今回のデータはkaggleの「Starbucks Customer Survey」のデータを利用します。
データの内容はマレーシアでとられたスターバックスの顧客調査データです。各データについては下記を参照してください。
| カラム名 | 内容 |
|---|---|
| Id | 一意の値(数値) |
| gender | 性別(0: 男性, 1: 女性) |
| age | 年齢(0: 20未満, 1: 20 – 29, 2: 30 – 39, 3: 40以上) |
| status | 職業(0: 学生, 1: 自営業, 2: 雇用, 3: 主婦) |
| income | 所得 (0: RM25,000未満 1: RM25,000 – RM50,000 2: RM50,000 – RM100,000 3: RM100,000 – RM150,000 4: RM150,000より多い ) |
| visitNo | 利用頻度(0: 毎日, 1: 毎週, 3: 毎月, 4: 利用無し) |
| method | 利用内容(0: 食事, 1: ドライブスルー, 2: 持ち帰り, 3: 利用無し, 4: その他) |
| timeSpend | 滞在時間(0: 30分未満, 1: 30分から1時間, 2: 1時間から2時間, 3: 2時間から3時間, 4: 3時間以上) |
| location | 場所(0: 1km以内, 1: 1km〜3km, 2: 3km以上) |
| membershipCard | メンバーカード(0: あり, 1: なし) |
| itemPurchaseCoffee | コーヒーの購入(0: あり, 1: なし) |
| itempurchaseCold | アイスコーヒーの購入(0: あり, 1: なし) |
| itemPurchasePastries | お菓子の購入(0: あり, 1: なし) |
| itemPurchaseJuices | ジュースの購入(0: あり, 1: なし) |
| itemPurchaseSandwiches | サンドイッチの購入(0: あり, 1: なし) |
| itemPurchaseOthers | その他の購入(0: あり, 1: なし) |
| spendPurchase | 購入金額(0: ゼロ, 1: RM20未満, 2: RM20からRM40, 3: RM40より多い) |
| productRate | 製品評価(非常に悪い 1 – 5 非常によい) |
| priceRate | 価格評価(非常に悪い 1 – 5 非常によい) |
| promoRate | プロモーション評価(非常に悪い 1 – 5 非常によい) |
| ambianceRate | 雰囲気評価(非常に悪い 1 – 5 非常によい) |
| wifiRate | wi-fi評価(非常に悪い 1 – 5 非常によい) |
| serviceRate | サービス評価(非常に悪い 1 – 5 非常によい) |
| chooseRate | 食事以外で選択するか評価(非常に悪い 1 – 5 非常によい) |
| promoMethodApp | 食事以外で選択するか評価(非常に悪い 1 – 5 非常によい) |
| promoMethodSoc | アプリから知った(0: はい, 1: いいえ) |
| promoMethodEmail | メールから知った(0: はい, 1: いいえ) |
| promoMethodDeal | チラシから知った(0: はい, 1: いいえ) |
| promoMethodFriend | 友達から知った(0: はい, 1: いいえ) |
| promoMethodDisplay | 表示広告から知った(0: はい, 1: いいえ) |
| promoMethodBillboard | ビル広告から知った(0: はい, 1: いいえ) |
| promoMethodOthers | その他でで知った(0: はい, 1: いいえ) |
| loyal | 購入を続けるか(0: はい, 1: いいえ) |
このデータからほしいなと思うものは、ユーザーが購入を続けるかどうかloyalもしくはどのくらいの頻度で来店するかvisitNoかなと思います。
今回はloyalに的を絞って、これを予測してみましょう!
まずは何も処理せずにどのくらい予測できるかを確認したいと思います。
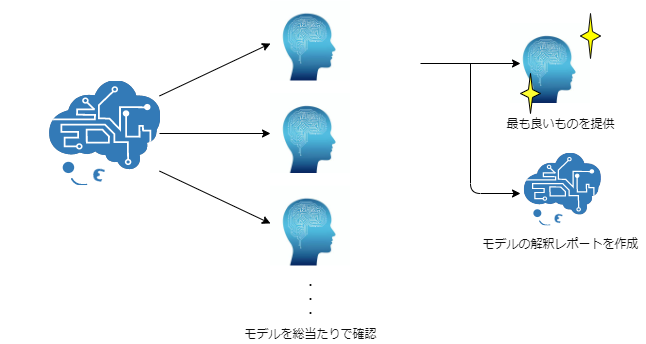
ナレコムAIを使って予測を行いたいので、ナレコムAIにデータを登録します。
 |
 |
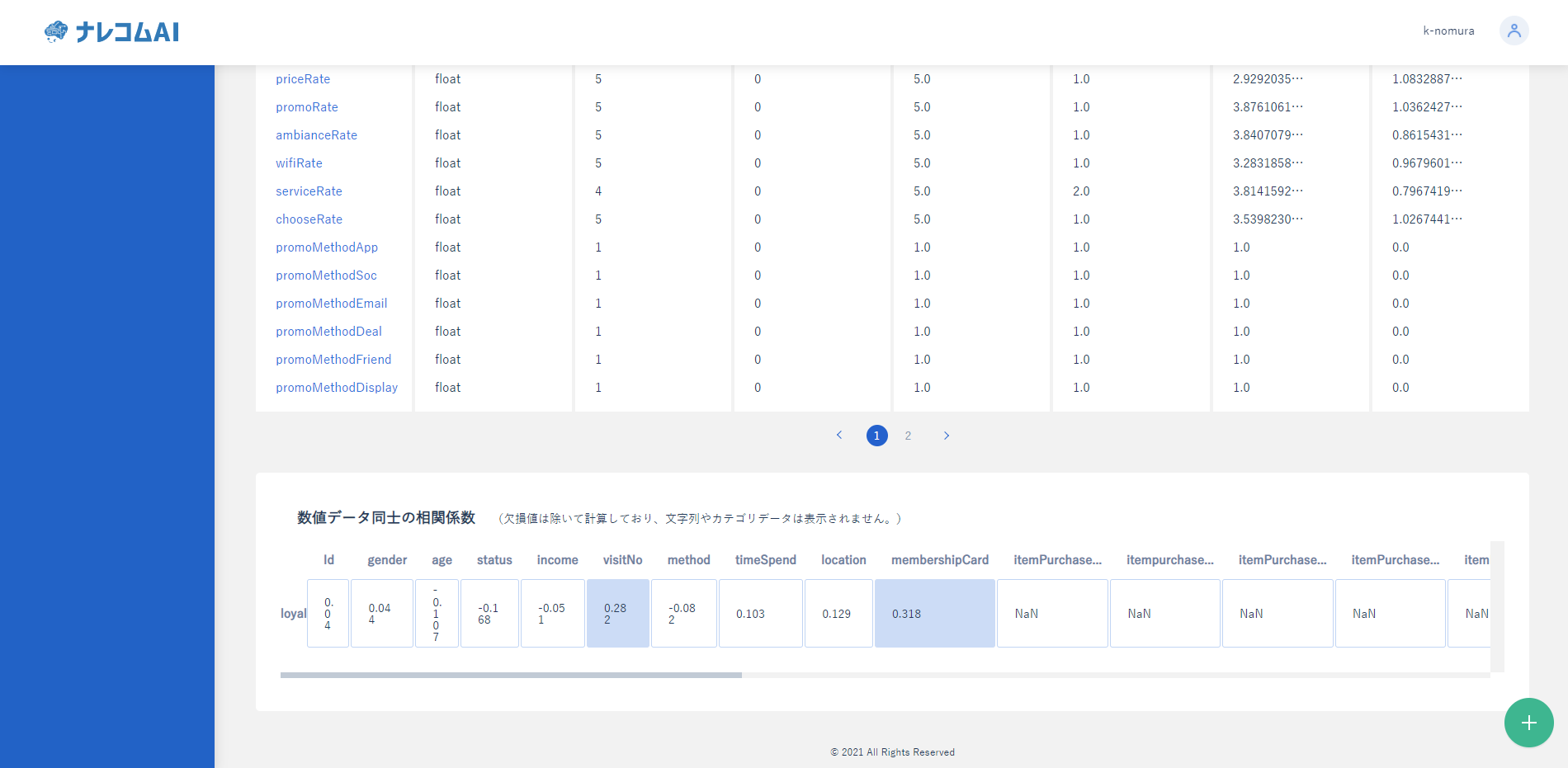
登録するとデータの詳細を確認することができます。
ここではデータの種類やデータ同士の相関を確認することができます。
予測対象が明確に決まっていないときなどは、この相関の値が大きいものを予測対象に選ぶと予測しやすいモデルが創れるかもしれません。
 |
今回は予測の対象をloyalと決めているので、いったんこのままモデルを作成してみましょう。
モデルを作成してみる
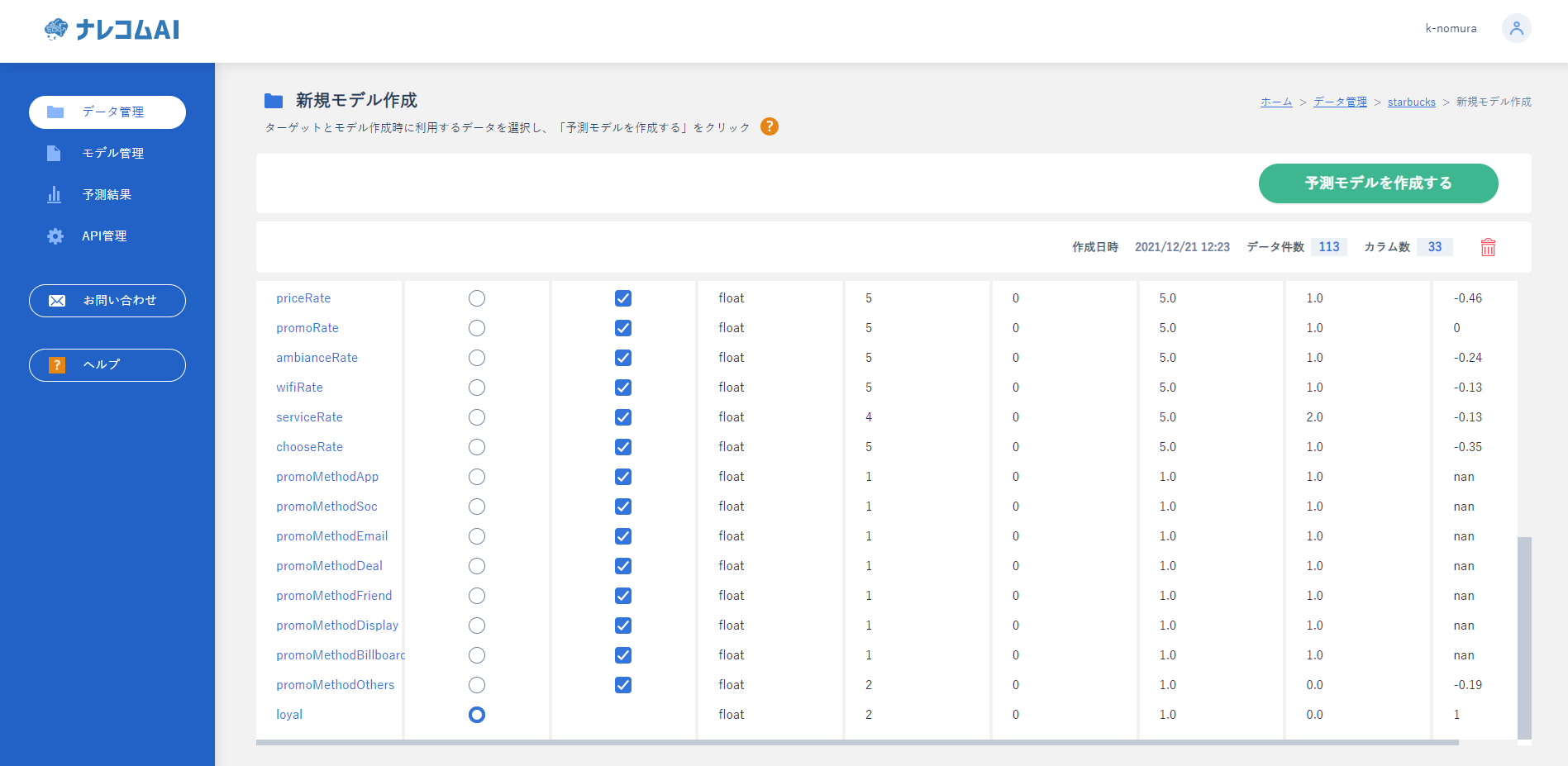
モデル作成ページからモデルを登録します。
モデル作成は画面左上の「このデータでモデルを作る」から作成が可能です。
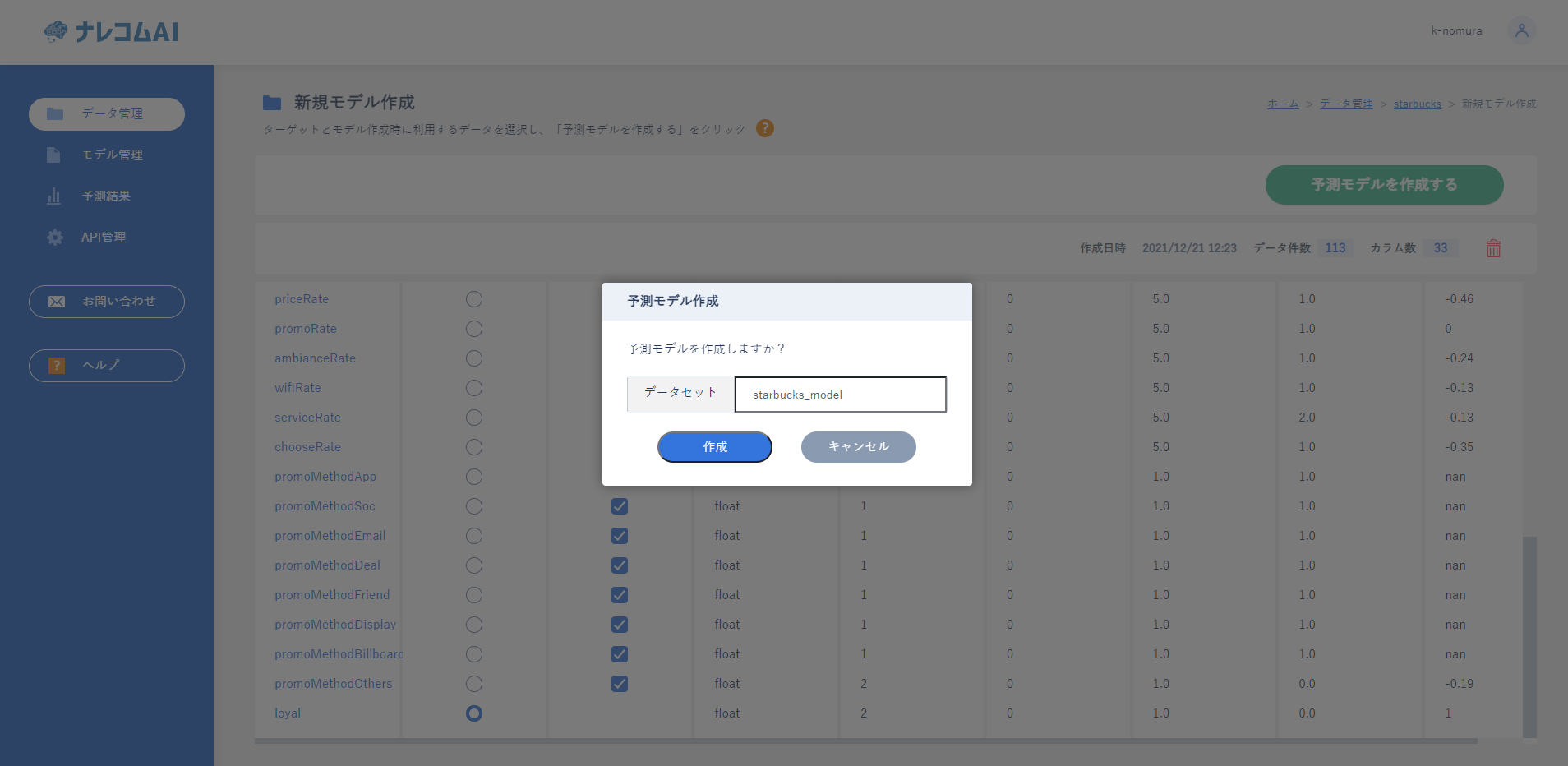
作成ページでは予測したいもの(今回はloyal)と学習に利用するデータを選択します。
今回はすべてのデータを投入してみたいと思います。
 |
 |
 |
実行するとモデルの作成が開始され、上記のようになると作成が終了したことになります。
今回のデータ量(113個)だと大体3分程で作成できます。
作成したモデルをクリックすることでモデルの評価を確認することができます。
ナレコムAIでは、グラフや解説文などを表示しているので、初めてAIを利用する人でもモデルの特徴を理解しやすくなっています。
モデルを評価してみる
それでは今回のモデルを評価してみましょう。
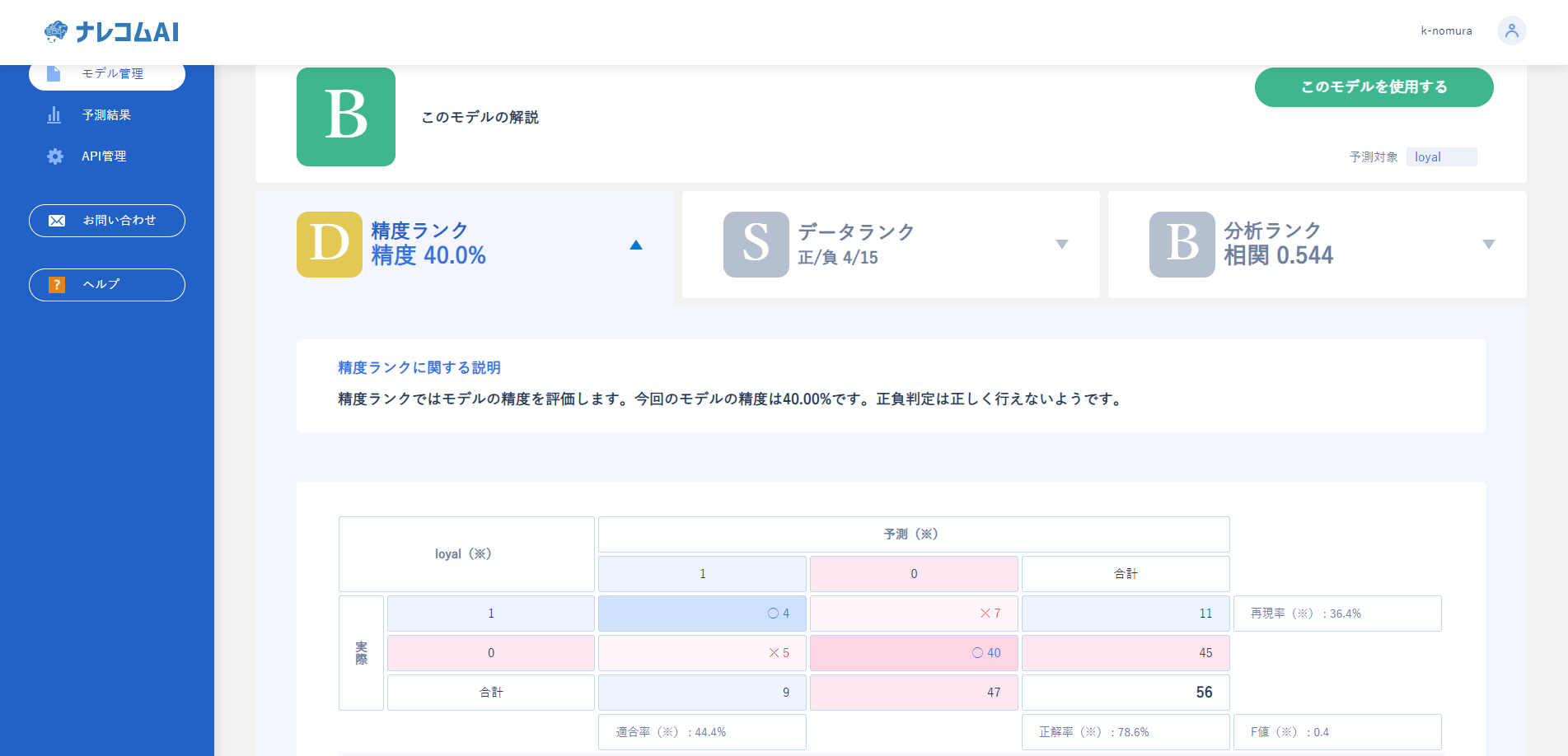
まず精度の評価ですが、あまりよくないようです。
精度があまりよくないので詳しく見てみたいと思います。
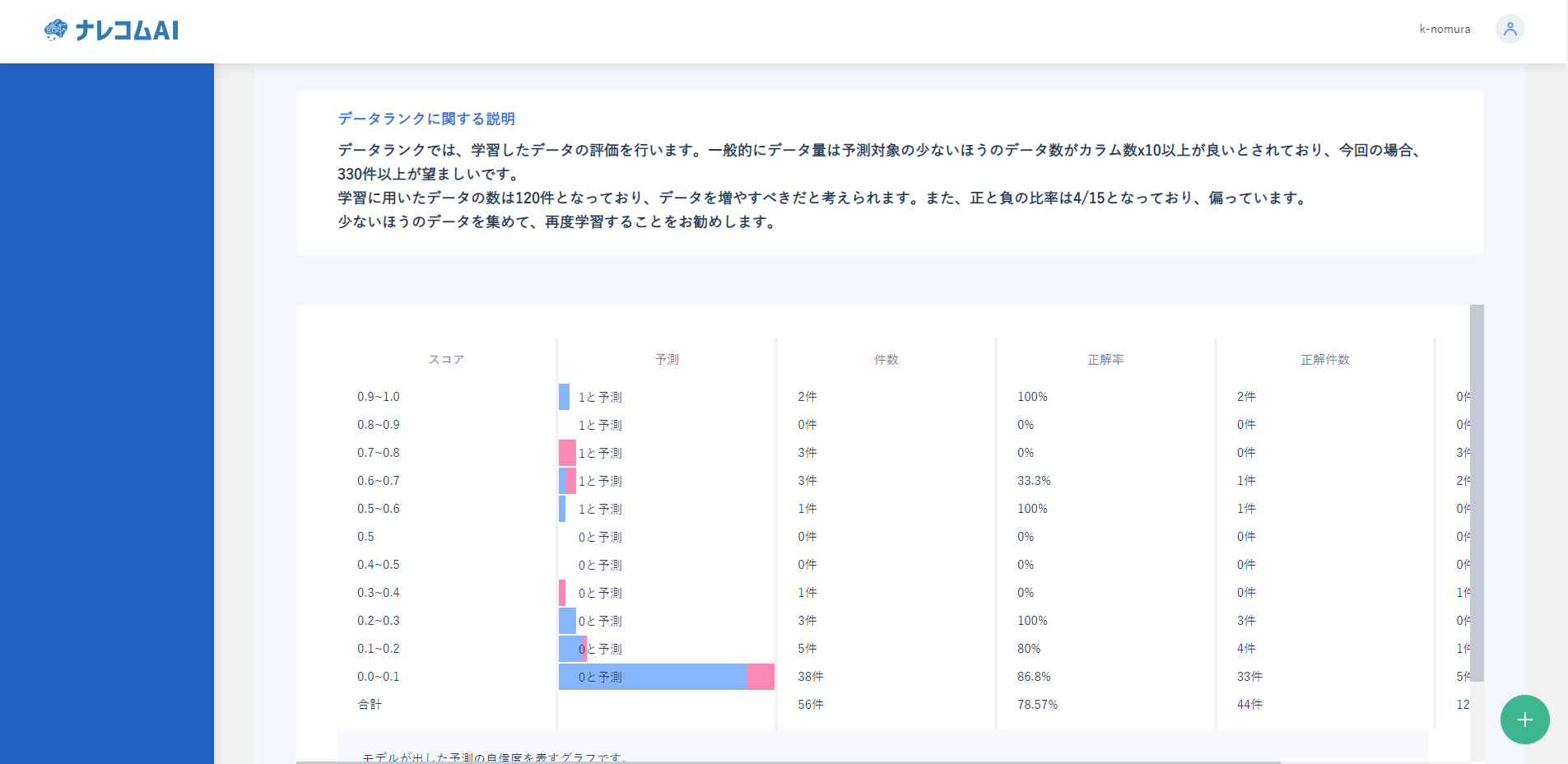
データランクを見てみるとデータのバランスがかなり悪いことがわかります。
「1」と「0」のバランスが4:15ととても偏っています。
このため、AIはとりあえず0と予測しておけば正解率が高い!と思ってしまうのです。
結果、0と判定してしまい、予測が外れる個数が多くなっているのです。
さらにデータの数量についても言及されており、330件以上が望ましい中120件しかないということです。
 |
 |
最後に分析ランクを見てみましょう。
分析ランクでは各カラムの精度やデータの分布を確認できます。
今回はitemPurchaseCoffeeについて見てみましょう。
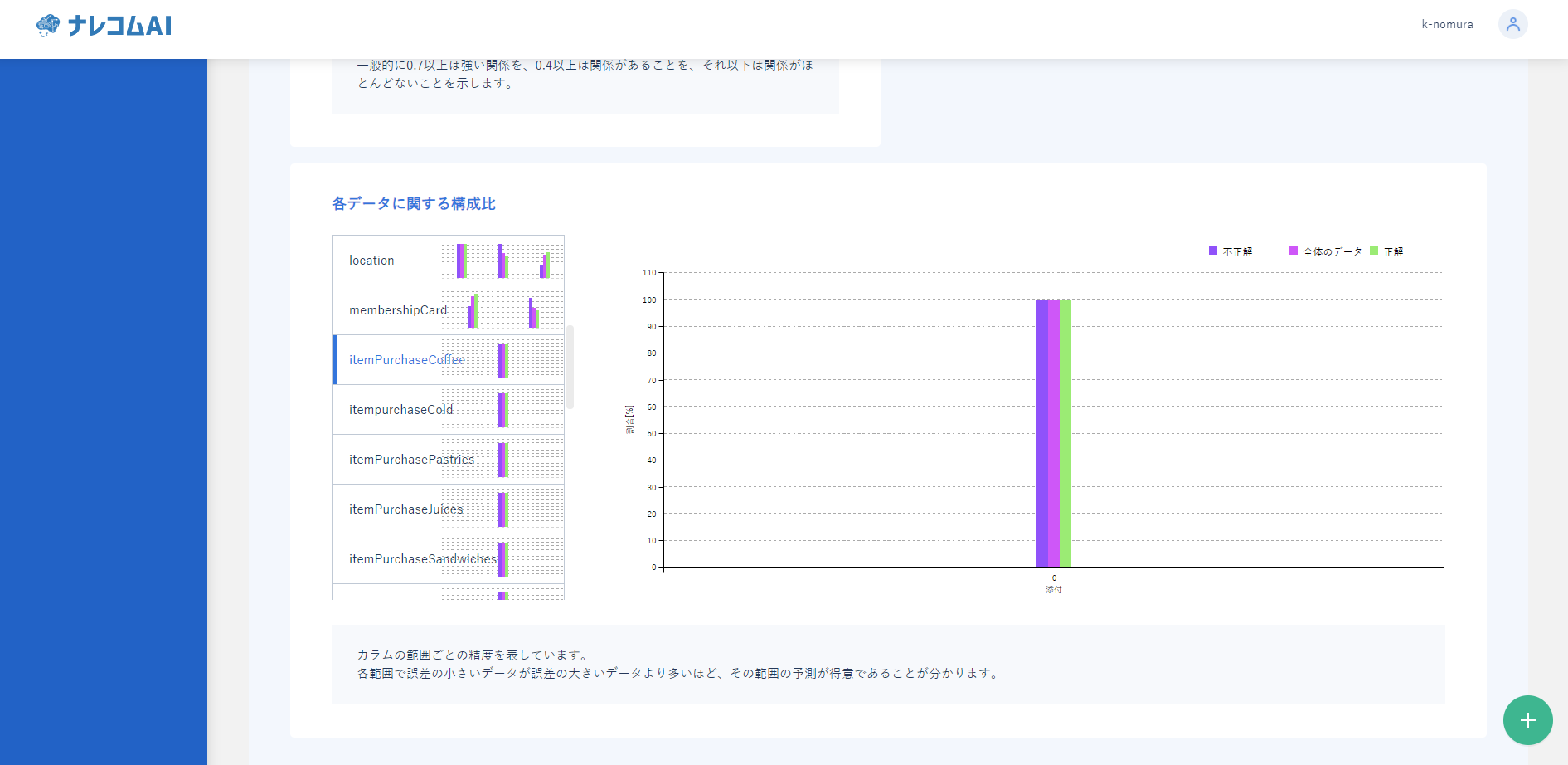
データの種類の項目が1つだけとなっています。
どうやら元から「0」のデータしかなかったみたいです。
このようにデータが1つしかないデータ、もしくはすべて異なるデータなどは学習する際に邪魔になることがあるので省いたほうがよいでしょう。
このようにデータが単一のカラムやすべて異なったカテゴリカルデータは、学習から取り除いたほうがいいと思われます。
読み取った内容から前処理の内容を決め、処理する
では読み取った内容からどのような処理をするのか決めましょう。
今回は以下の2つを行いたいと思います。
1. 必要ないと思われるデータの削除
2. 不均衡データを均一にする
一つ目についてですが、こちらはモデル作成時にクリックすることで除外することができるので、データをいじる必要はありません。
なので実際にデータにする処理は二つ目のデータを均衡にする処理になります。
不均衡データの処理方法としていくつか手法があります。
1. ダウンサンプリング(多いデータを削って少なくする)
2. アップサンプリング(少ないデータをかさましして増やす)
3. SMOTE(多いデータを削り、少ないデータをかさましする)
などが有名だと思います。
今回のデータは113個ととても少ないため、データの量を増やす際によいデータを生成できないと思ったので、ダウンサンプリングで処理したいと思います。
再度モデルを作成して、評価する
データ登録の手順は先ほどと同じため割愛します。
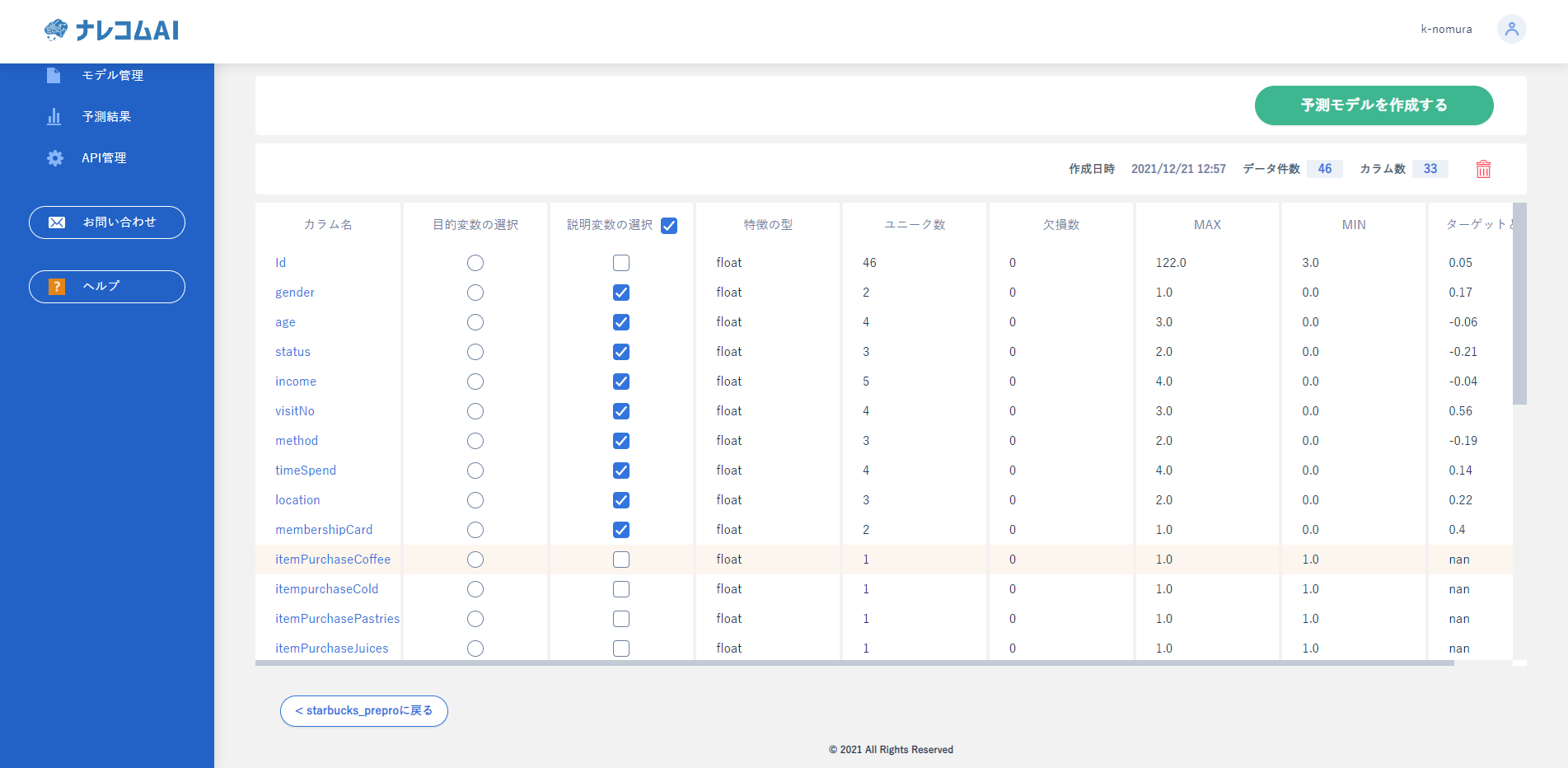
モデル作成時に省きたいデータをクリックすることで学習から除外することができます。
単一のデータはユニーク数を見ると1になってることがわかります。これを参考に除外していきましょう。
同様にすべて異なるデータはデータ数と同様の数値になっています。数値データの場合は問題ありませんがカテゴリカルデータ(ID
IDなど)の場合はすべて異なっていると意味がないことが多いので除外しておきます。
そしてできたモデルがこちらになります。
精度はかなり向上したように見えますね。
詳細を見てみましょう。
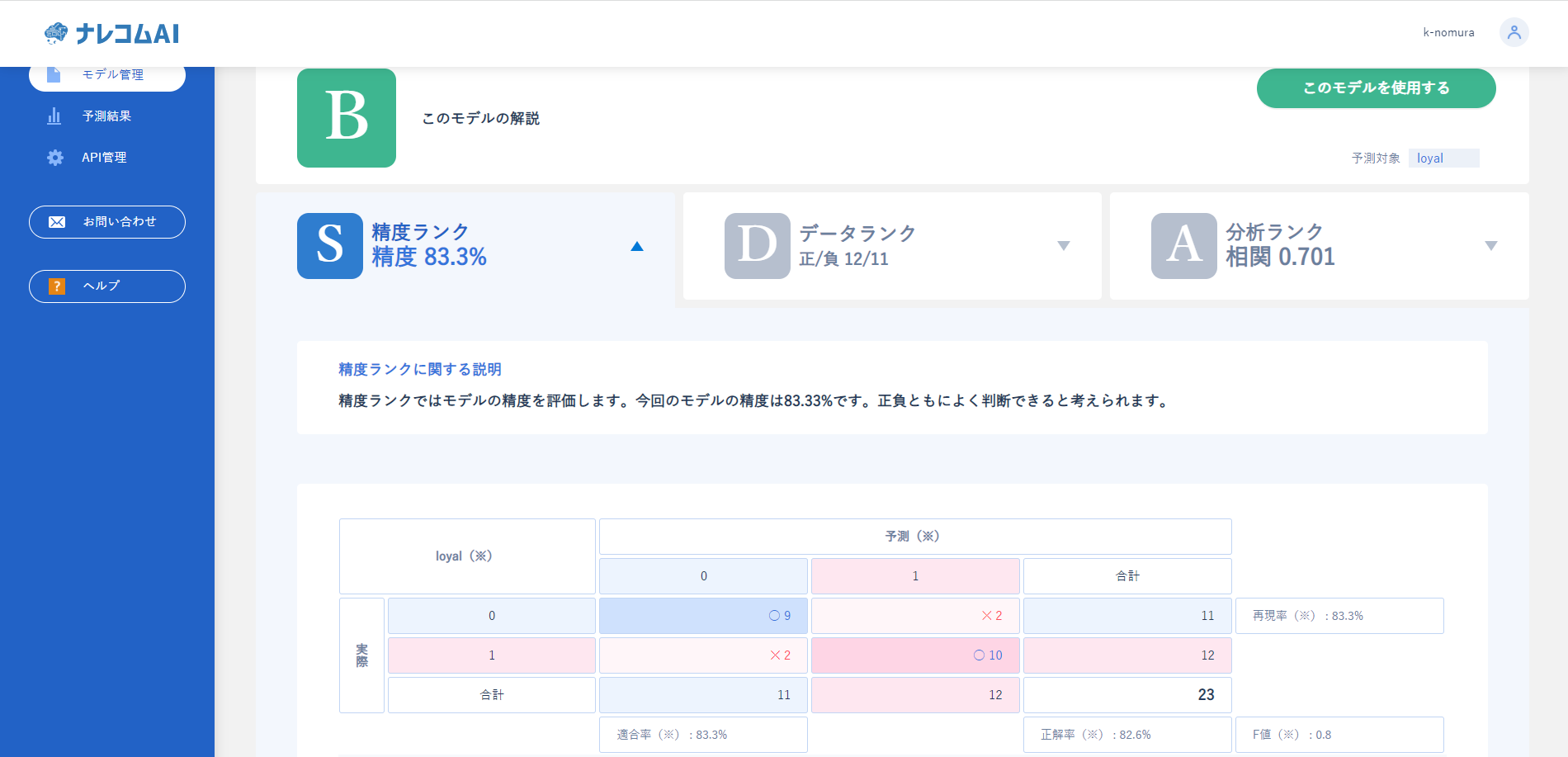
精度ランクを見ると再現率やF値など評価指標はどれも8割を超えており精度がよくなったことが読み取れますね。
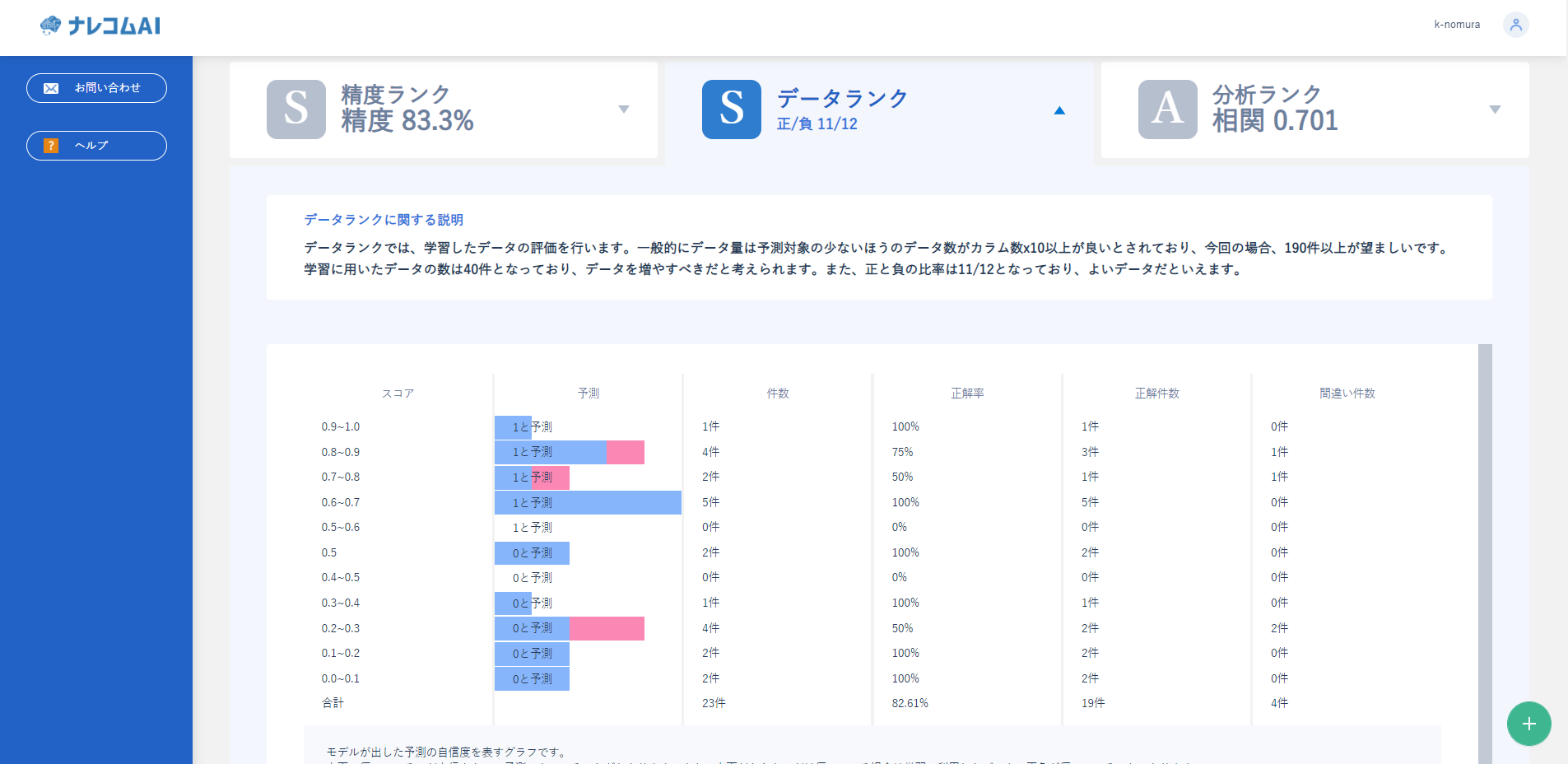
つづいて、データランクで作ったデータの評価を見てみましょう。
データのバランスは11:12とほぼ均衡しています。しかしダウンサンプリングを行ったことでもともと少なかったデータがさらにヘリ、40件となっています。
予測の分布についてもスコアがばらついており、自信のある予測ができていないようです。
しかし、よい精度自体はできているので同様のデータを収集し、母数を増やすことでよりよいモデルを作成できることが期待できます。
 |
 |
まとめ
今回はデータの数が少ないスターバックスの顧客調査データから継続利用するかを予測するモデルを作ってみました。
データの詳細がわからなくてもすぐにモデルを作成でき、その結果を踏まえて前処理の内容を決めることができました。
結果精度はよくなったものの、やはりデータ数が少ないことが原因で不安定かなという結論を得ることができました。
次回はデータの数が豊富なものを利用して、予測を行っていきたいと思います。