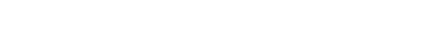
AutoMLツールナレコムAIでは、モデルの作成後レポートを確認することができ、モデルの特性をつかんだりより良いモデルを作るための参考にすることができます。今回の記事では二項分類モデルのレポートの読み方を実際の画面を交えて解説します。
レポートの種類
ナレコムAIには「精度」「データ」「分析」の3つの指標に分けて評価を行っています。
| ランク名 | 利用用途 |
|---|---|
| 精度 | 予測精度の確認、運用の判断 |
| データ | 学習に利用したデータの評価 |
| 分析 | より良いモデルにするための確認 |
今回利用するデータについて
今回利用するデータはKaggleの国勢調査のデータを利用します。
精度ランクの読み方
それでは精度ランクを確認していきましょう。
評価の文章を読んでみると、精度は72%となっており高い数値が出ています。
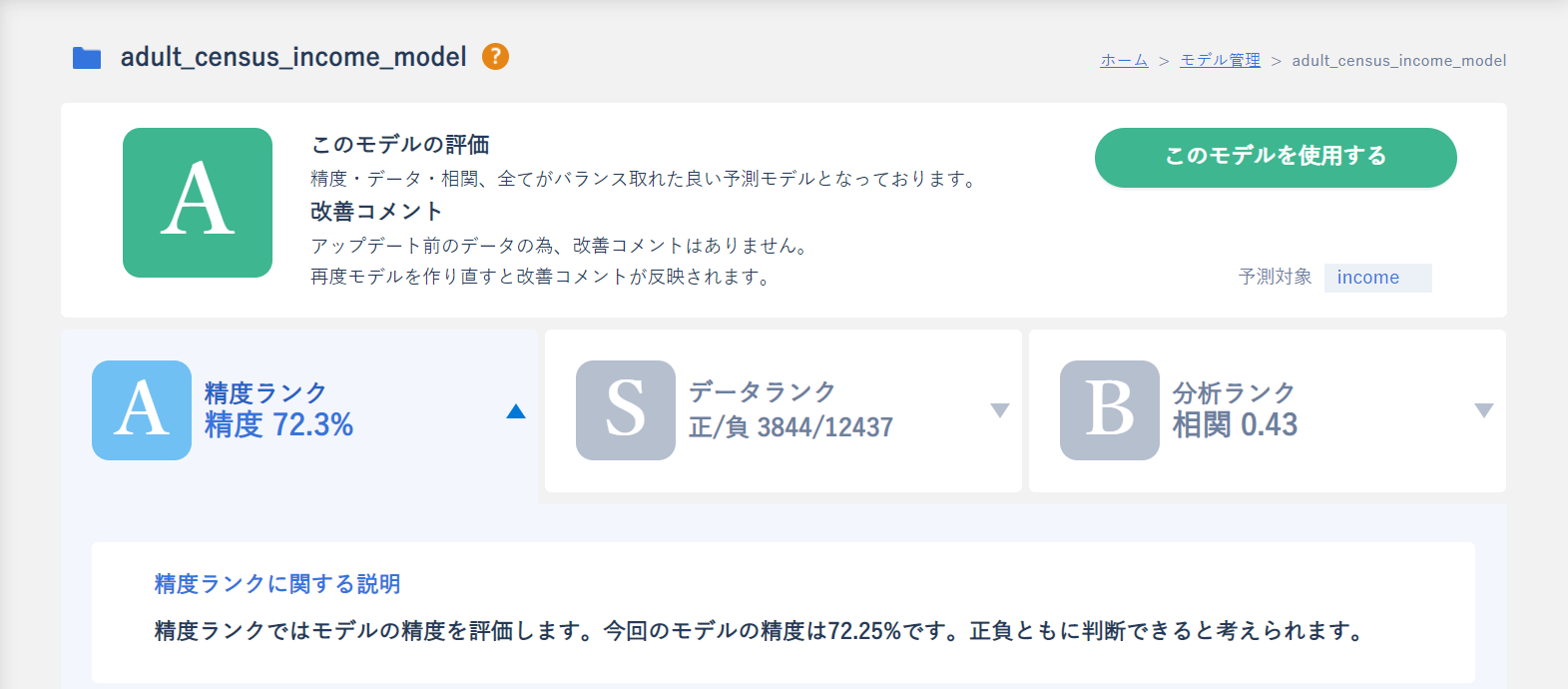
続いて表を読み取っていきましょう。
この表は混合行列といい、二項分類の精度評価を行う際に確認するものになります。
この中の「適合率」「正解率」「再現率」「F値」が精度指標であり、用途に応じて参照する指標を変えることでより運用に合ったモデルを選定できます。
では、どのような時にどの指標を利用するべきかを見ていきましょう。
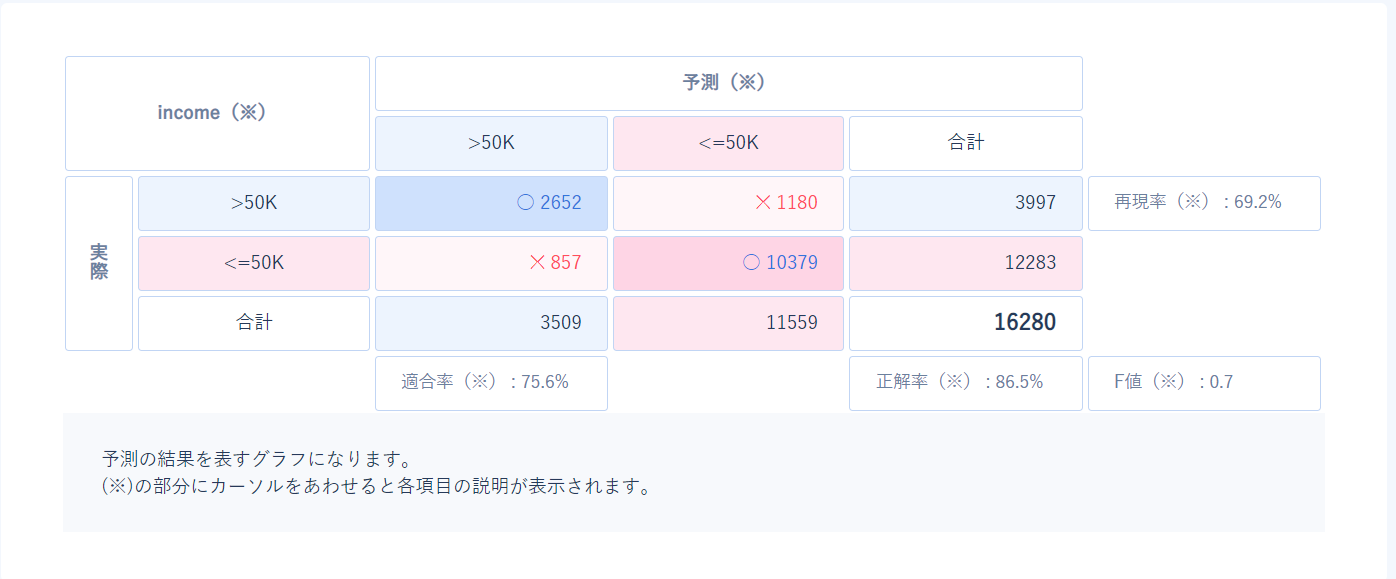
再現率(TP/(TP+FN))
再現率は実際に正であるデータのうち正しく正であると予測できたデータの割合を表します。
つまり、実際に正である値をどれだけとり逃すことなく予測できたかを表す指標です。
レコメンドのように、可能性があるものは少しも取り逃したくないというときに参考にするとよいでしょう。
(緑枠は正と予測したデータを表してます。)

注意点として、再現率100%でも大量に負を正と誤って予測することがあるので気をつけましょう。
適合率(TP/(TP+FP))
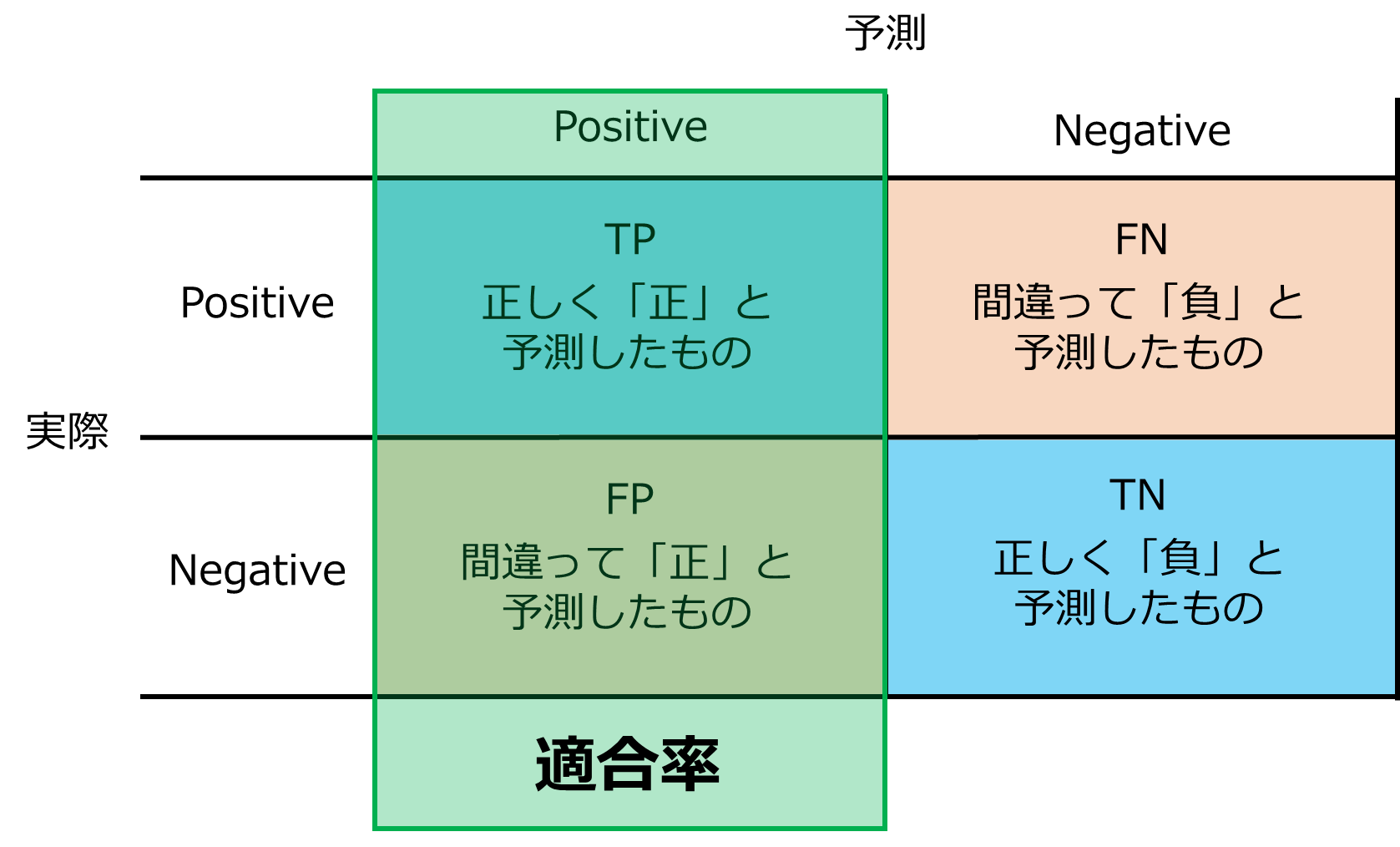
適合率は正と予測したデータのうち実際に正だったデータの割合を表します。
つまり、正と予測したものがどれだけ正しかったかを表す指標です。
正と予測したものが必ず正であってほしい場合に参考にするとよいでしょう。
(緑枠は正と予測したデータを表してます。)

注意点として、適合率が100%でも大量に正解をとり逃すことがあるので気をつけましょう。
F値((2×再現率×適合率)/(再現率+適合率))
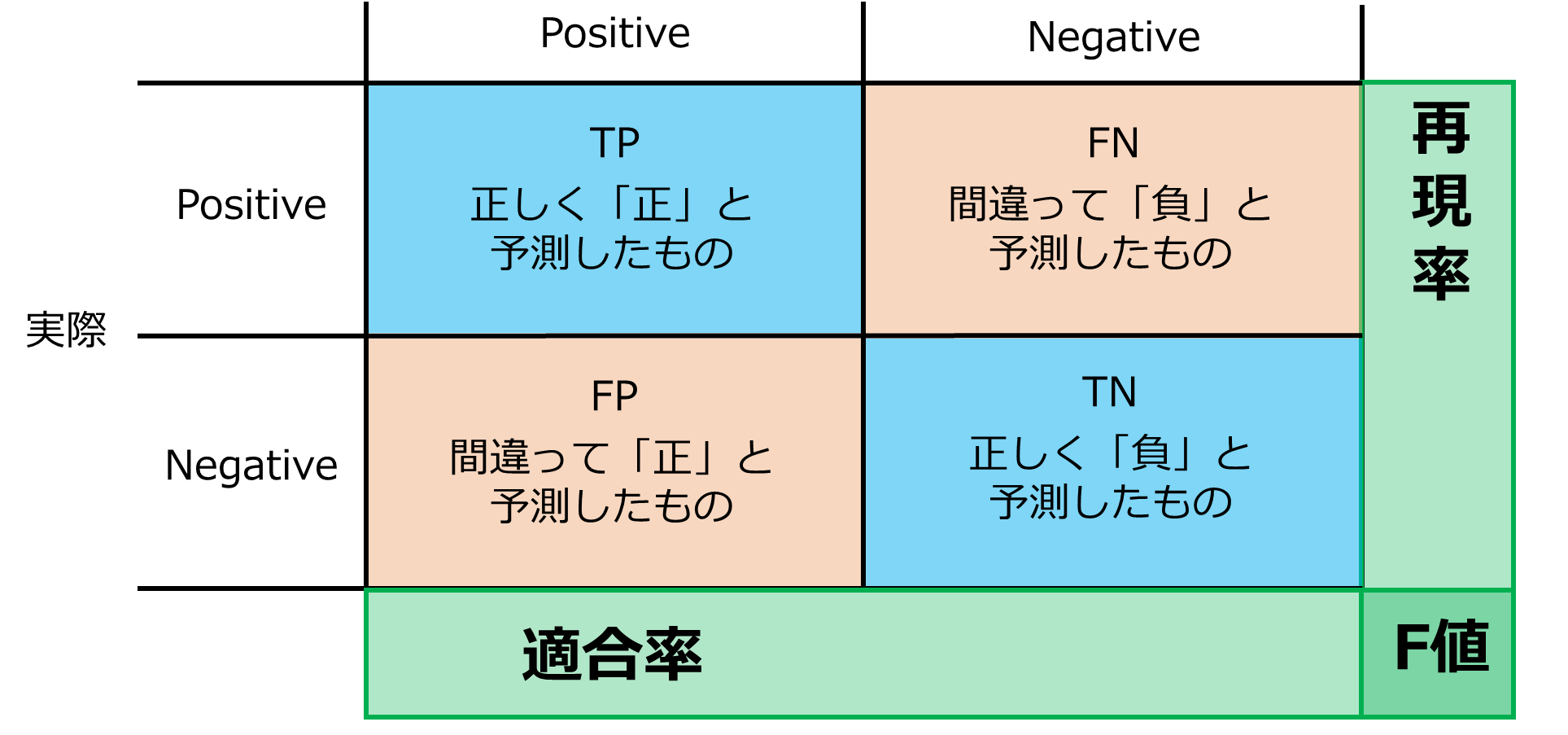
F値は再現率と適合率の調和平均をとったものです。
調和平均とかいう難しい言葉を使ったいますが、要するにこの二つの指標をバランスよく判断している、と思っていいと思います。
(緑枠は正と予測したデータを表してます。)

上の図のようにF値はどれだけ正のデータを正しく予測できているか、を表す指標になります。
正の予測が外れたり、負のデータを誤って正と判断するとこの評価値は下がっていきます。
特に使用用途が決まっておらず、精度を求めたいときはF値を参考にするといいかもしれません。
正解率((TP+TN)/(TP+TN+FP+FN))
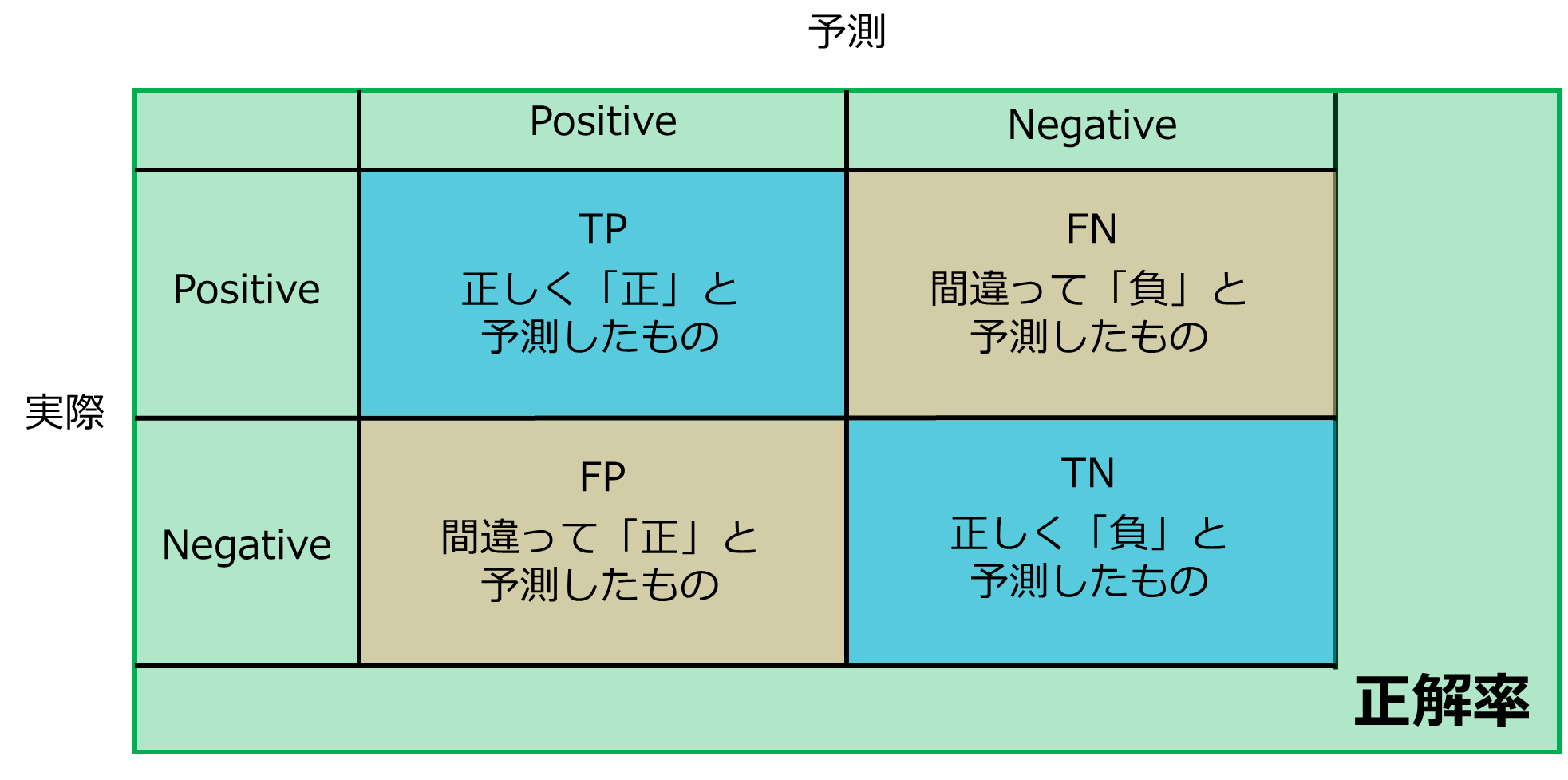
正解率はすべてのデータのうち正しく予測できた割合を表しています。
一見それらしい値に見えますが、欠点があります。
(割合の表示がミスってたので更新しました)
(緑枠は正と予測したデータを表してます。)

ここにデータ量が偏ったデータがあったとします。
このモデルは常に正と予測するだけのモデルですが、正解率は90%と出てしまいます。
このようにデータの偏りによってよさそうな値でもよいモデルとは限らないことがあります。
データが偏っておらず、かつ正、負ともに正確に予測したい場合には正解率を利用してもいいのかもしれません。
今回のモデルで何をしたいかによって指標を決める必要があります。
例えば収入によって契約の有無を判定するのであれば、誤ってOKにするのは問題となるでしょう。
であるならば、適合率を重視することで高確率でOKのデータのみをとれるようにするとよいことが分かります
データランク
続いてデータランクを確認してみましょう。
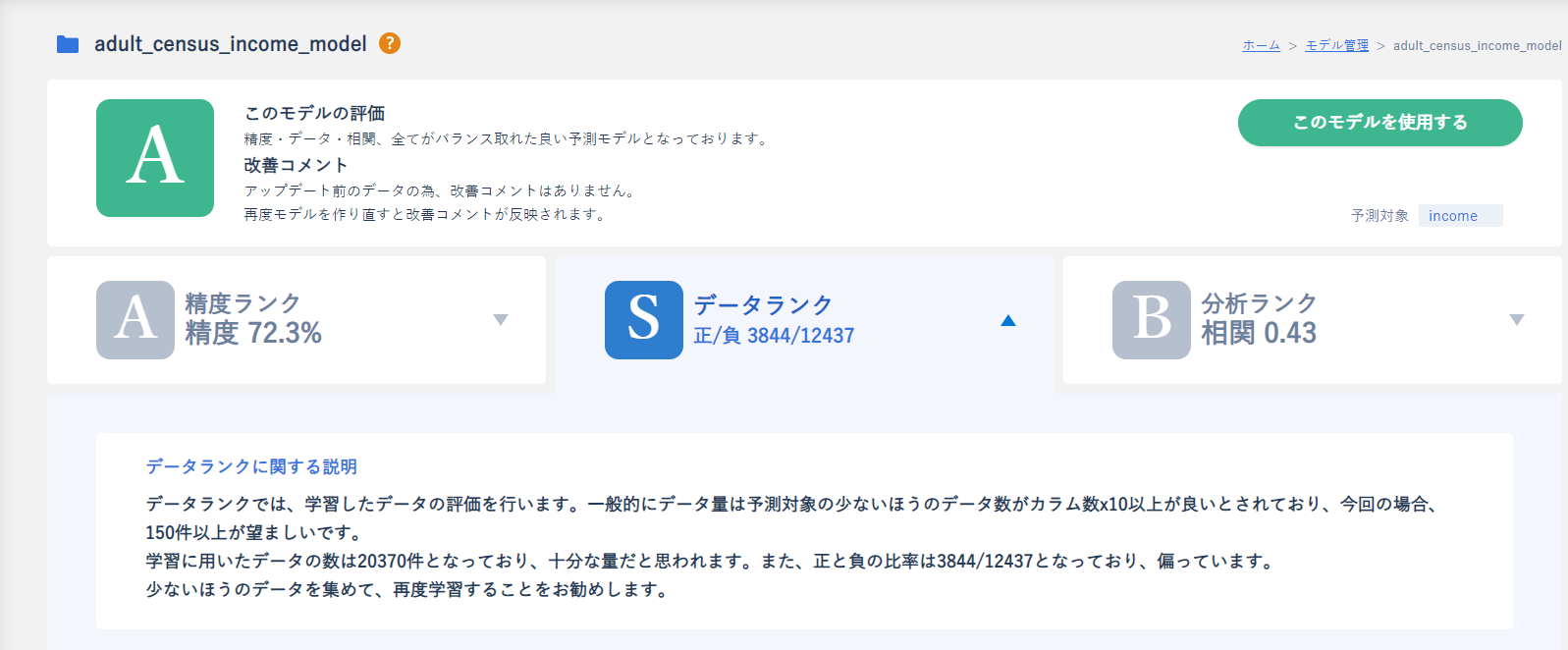
文章を確認してみたらデータの量は十分であり、データの偏りがあるらしいです。
これを参考に学習時のデータに対して前処理をする参考にすることができます。
今回のデータは量が多くバランスが悪いため、負のデータを削減することでバランスを整えるダウンサンプリングをするとよいと考えられます。
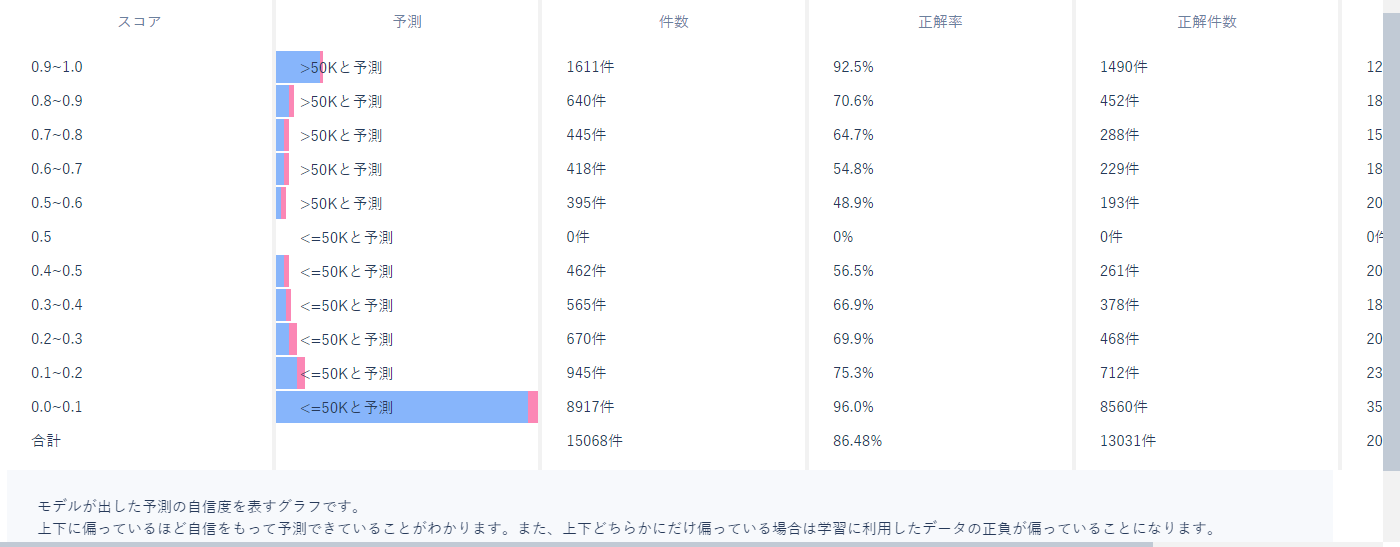
グラフを見てみると、青い帯が多いことが分かります。
青い帯は正解データを表すため多くのデータは正しく予測できていることが分かります。
グラフ内のスコアという項目は、モデルがどれほど自信をもって正負の判断をしているのかを表す数値です。
1に近いほど自信をもって正、0に近いほど自信をもって負と予測していることを表すため、上下に帯が固まっているほど良いモデルとなります。
今回のデータだと上下に行くほどデータが集まっているのでよいモデルです。
分析ランク
最後に分析ランクを確認してみます。
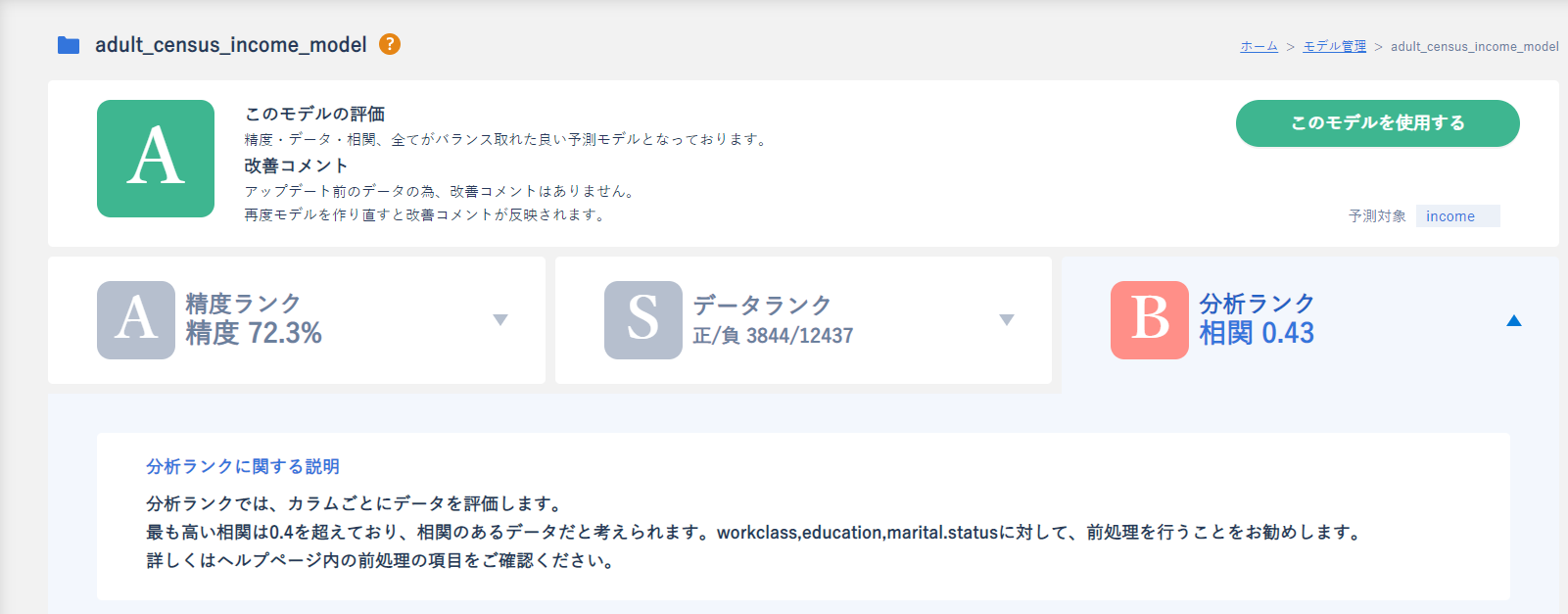
文章を確認してみると高い相関を持つデータがありよいデータであることがわかりました。
また、特定のカラムに対して前処理したほうがいいことがわかります。
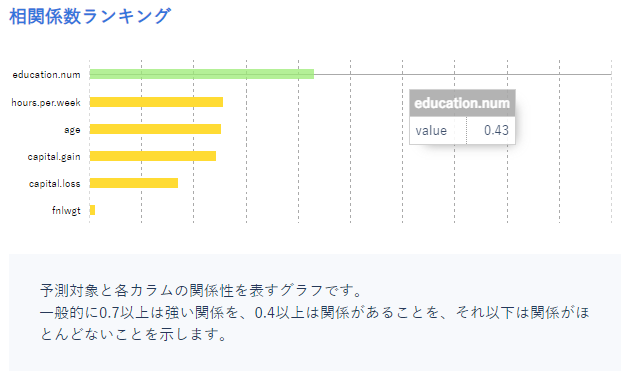
次に相関を確認してみましょう。
緑のデータは弱い相関を表しており、黄色のデータはほとんど相関がないことを表しています。
もし学習データの取捨選択を行う場合はこの相関の高いデータは残したほうがいいかもしれません。
また、相関の高すぎるデータは予測時にはわかっていないデータの場合があります。
その場合運用することができないため、あらかじめデータを見直すことが大切です。
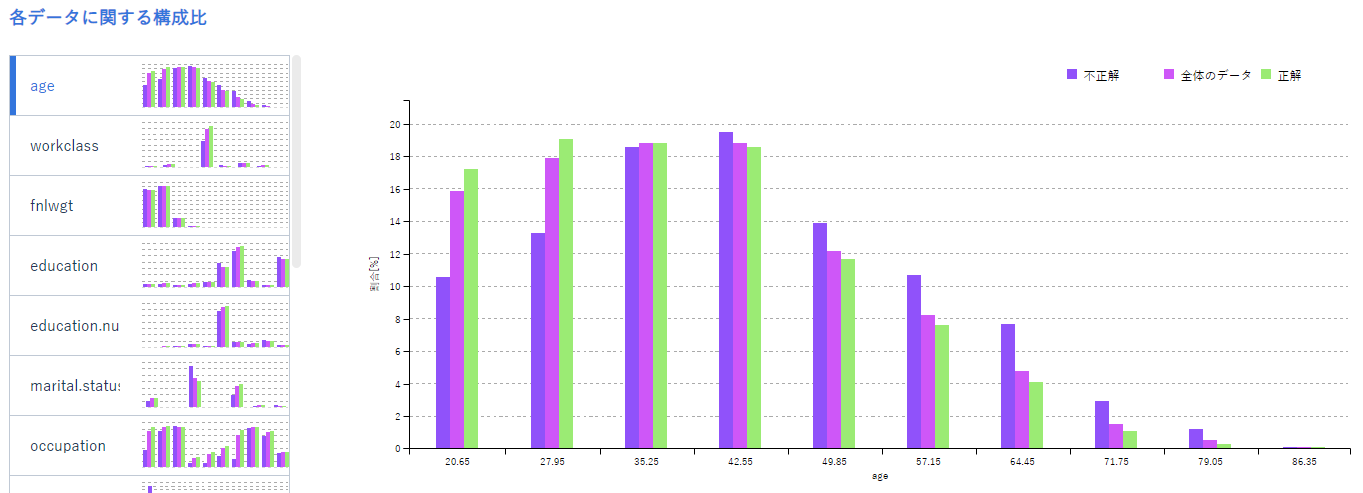
続いて構成比グラフです。
このグラフは誤差の大小とデータ全体の3項目をデータごとにまとめたものです。
特定の項目において、どの値のとき誤差が小さくなるのか等がわかることで精度の高さに影響しているのかを知ることができます。
これにより、誤差の大きいデータの箇所は学習が十分でない可能性があるので重点的に収集したり、学習から取り除くなどの前処理をする参考にできます。
まとめ
以上で二項分類のレポートの解説を終了します。
運用の際に何を重視するかを考えたうえでもでるを作ることで、複数ある指標から選定することができるので、運用についてしっかり考えたうえでモデルの作成に取り掛かりたいですね。