はじめに
この記事では機械学習や統計をやったことはないけどAIを使ってみたい、といった方に向けた記事になっています。
機械学習にはプログラムや統計など知識の壁が大きく、またモデルの差育成に対する時間の壁も大きいかと思います。
今回利用するAutoMLツール「ナレコムAI」を利用することで5分ほどで簡単にモデルを作成でき、モデルの評価についても作成されるレポートを読むことでMLの知識がなくともモデルの特性やよいモデルにするためのアプローチ内容を把握することができます。「データはあるけど、活用できるかわからない」「AIについて興味があるけど敷居が高そう」と考えている方が、少しでも前進するきっかけになれたら嬉しいです!
なぜ高い精度のモデルが作成できるのか
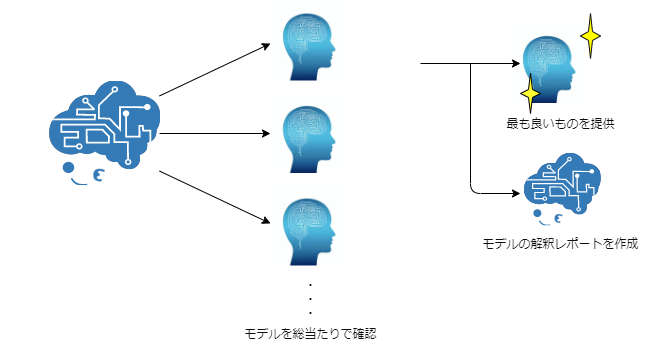
本来であればパラメータの選定やアルゴリズムについての学習、選定など知識や時間がかかってしまいます。
ナレコムAIでは事前に用意されたアルゴリズムやパラメータの組み合わせ数十種類をすべて試し、その中で最も良いモデルを提供しています。
そのため、パラメータの探索漏れなどがなく、精度の高いモデルの作成、提供を行うことができるのです。
さらに、データの登録からモデルの作成、モデルの解釈についてのレポートを作成するため、モデルの精度向上までを含めノーコードで行うことができます。
 |
データを見てみる
今回は銀行の顧客がキャンペーンに反応するかを予測してみようと思います。
データはSIGNATEの「【第1回_Beginner限定コンペ】銀行の顧客ターゲティング」を利用します。
まずはデータについて見てみましょう。
ナレコムAIにデータを登録することでデータの内容を確認できます。
 |
 |
まずは何も処理せずにどのくらい予測できるかを確認したいと思います。
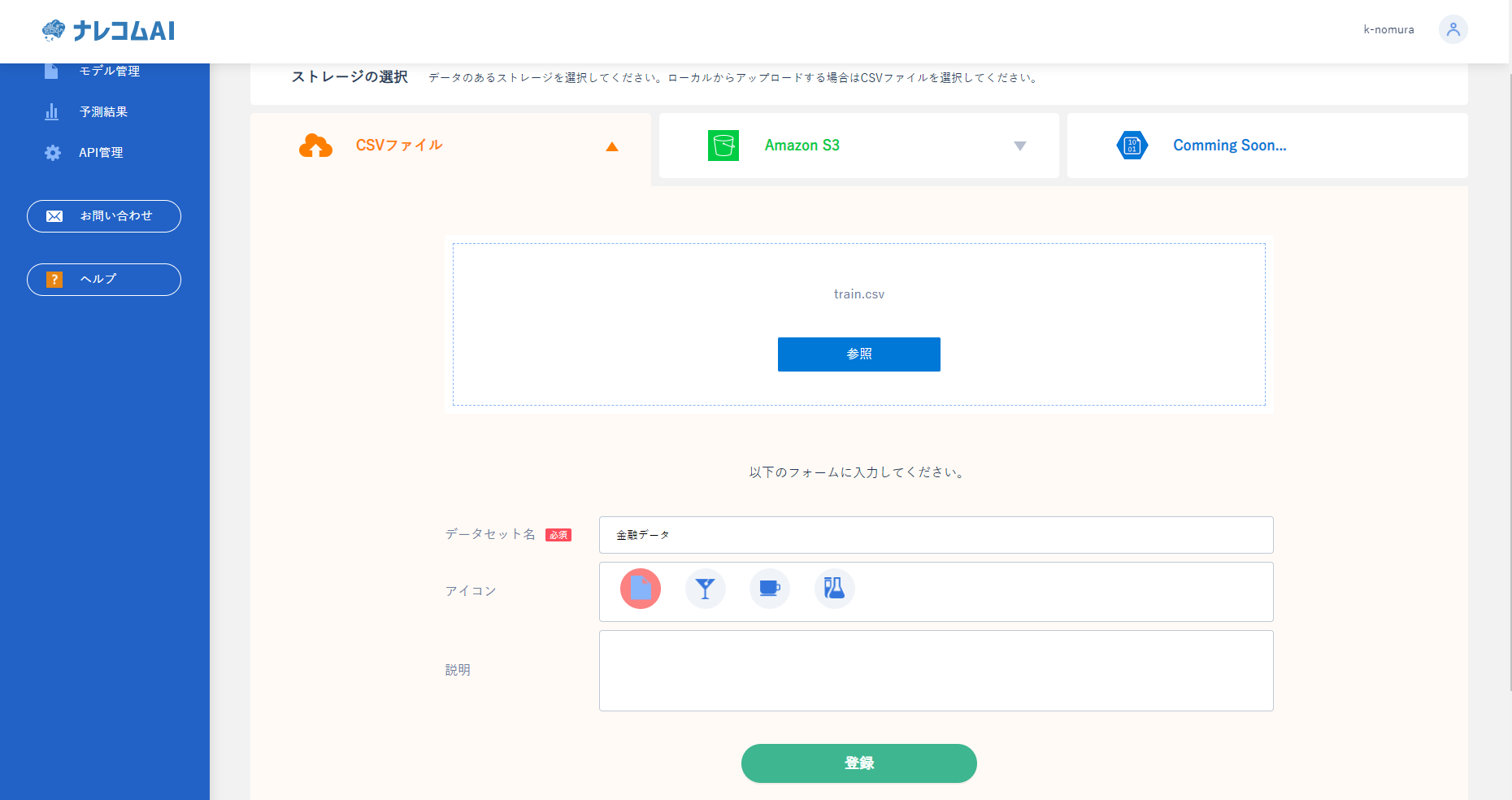
ナレコムAIを使って予測を行いたいので、ナレコムAIにデータを登録します。
まずはデータセット名を「金融データ」とします。次に学習に使うファイルを選択します。signateからダウンロードしたtrainデータを
選び、登録を押し、実行してよろしいですか?とでてくるのでOKを押します。
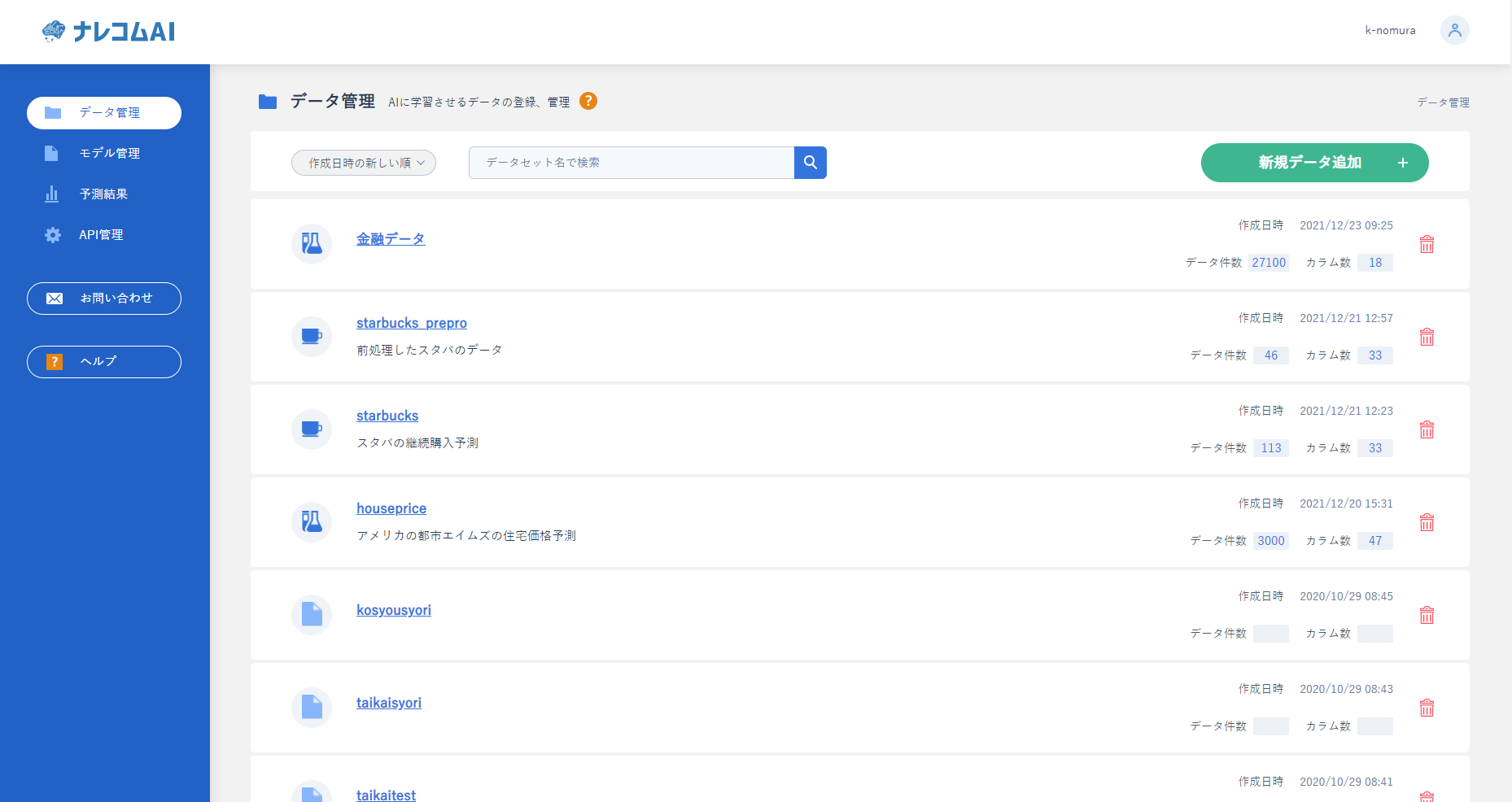
データが登録されるとデータの詳細を確認できるようになります。
実際に確認してみたいと思います。
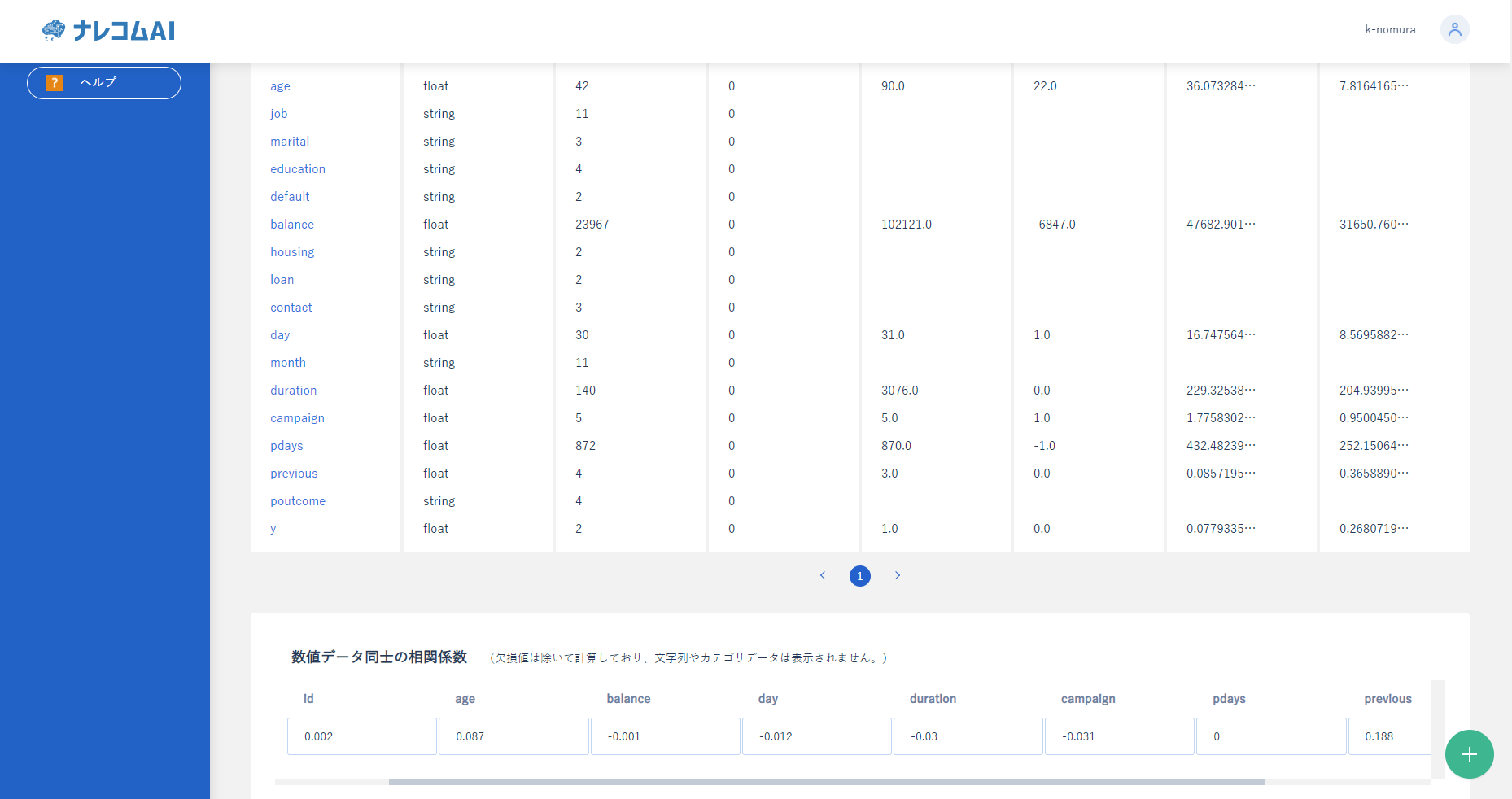 |
ここではデータの種類やデータ同士の相関を確認することができます。
どのようなデータが含まれているか確認したいときに便利です。
モデルを作成してみる
それでは実際にモデルを作成します。
先ほどのデータから予測したいカラムを選択します。
今回は「y」を選択しました。また、不要なカラムはここでチェックを外すことで学習から除外することができます。
データの選択には、横に書かれているデータを参考にするとわかりやすいです。
例えば、ユニーク数が1の場合、そのカラムにはデータが1種類しかないことになるので、省いてもよいデータであることがわかります。
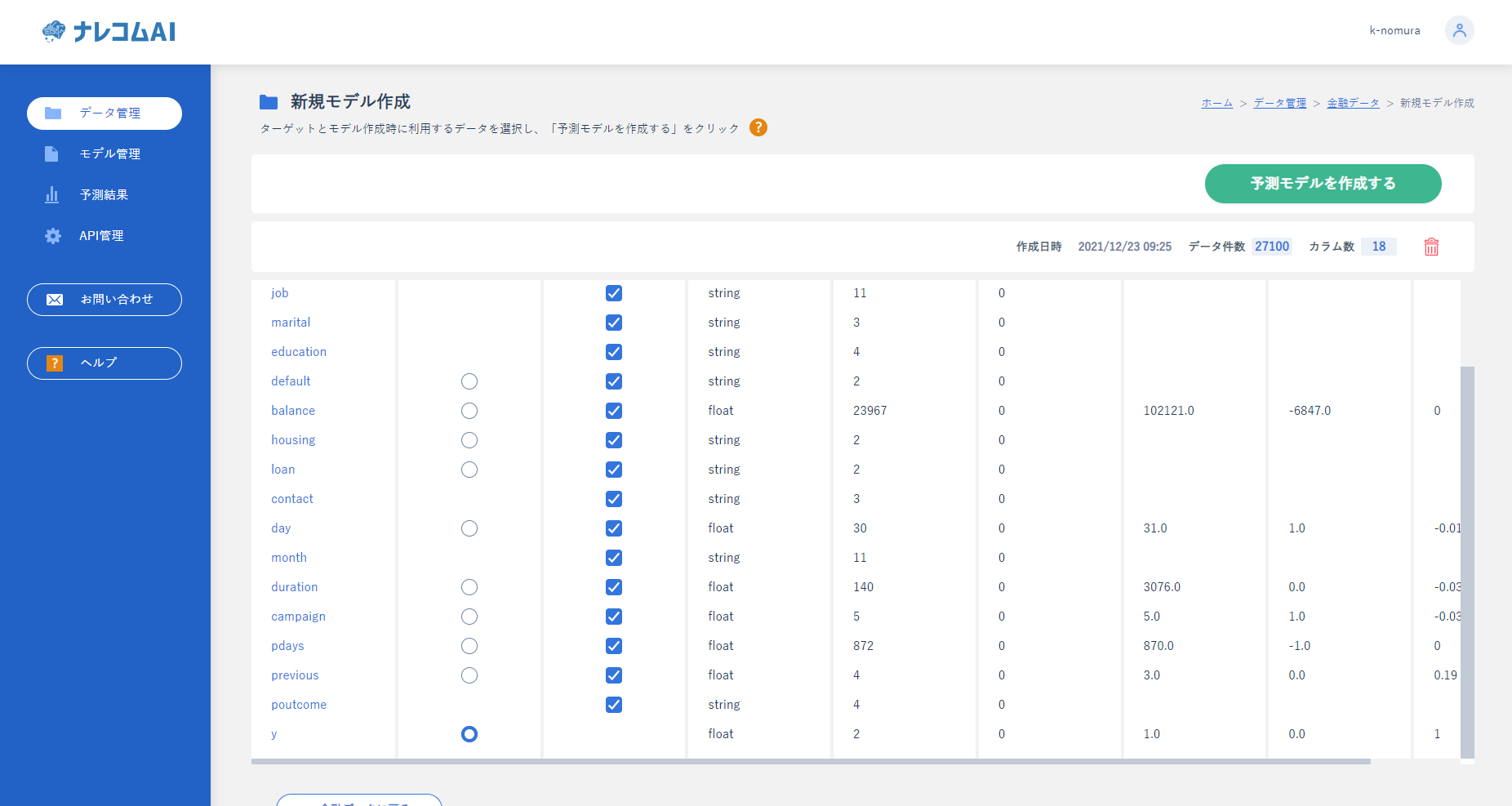 |
実行するとモデルの作成が開始され、上記のようになると作成が終了したことになります。
作成したモデルをクリックすることでモデルの評価を確認することができます。
ナレコムAIでは、グラフや解説文などを表示しているので、初めてAIを利用する人でもモデルの特徴を理解しやすくなっています。
モデルを評価してみる
それでは今回のモデルを評価してみましょう。
まず精度に関してですがあまり思わしくない結果になっているようです。
正解率自体は高いのですが、再現率、適合率、F値などが低くなっています。
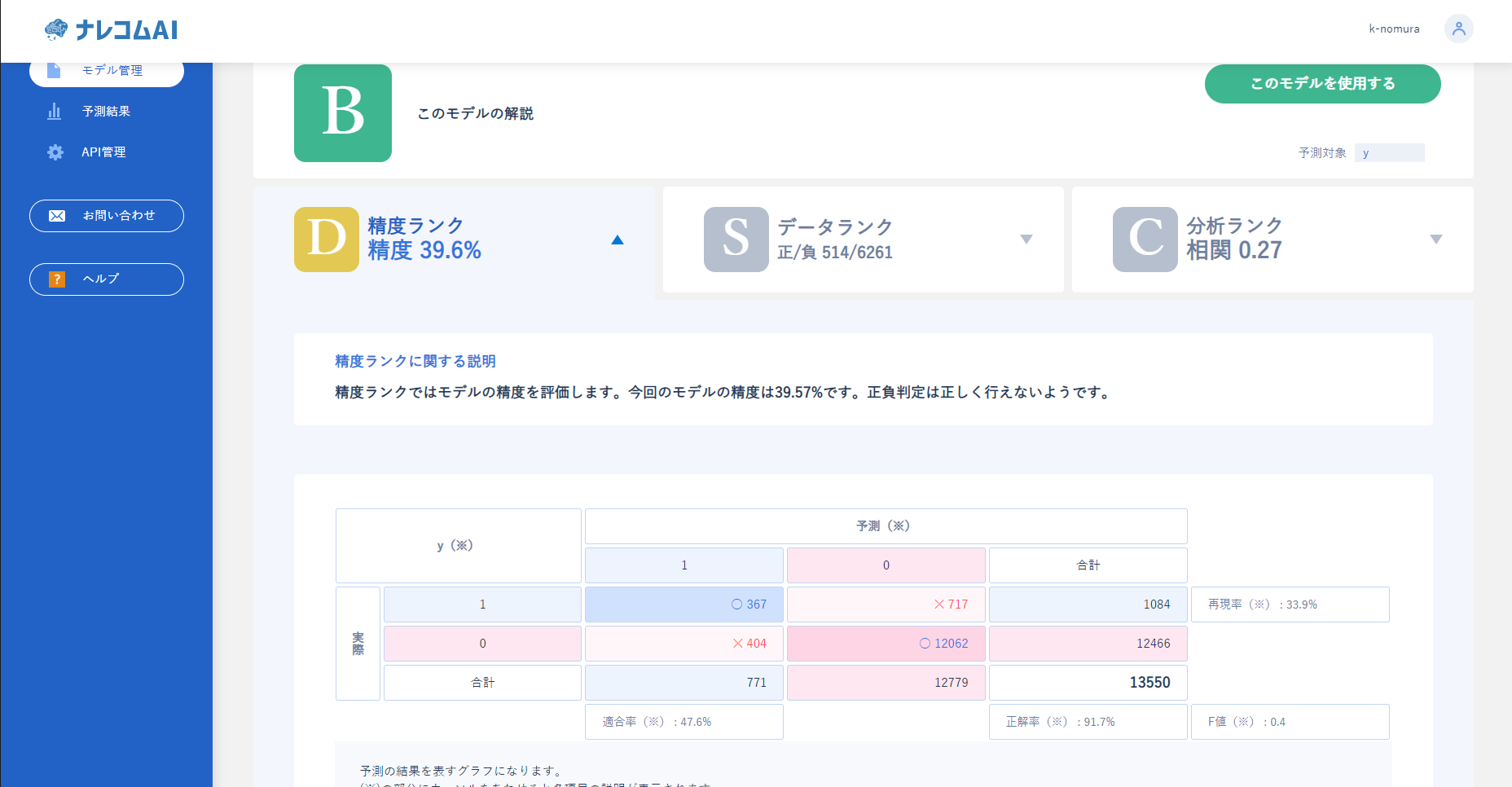 |
続いてデータについて見てみたいと思います。
データ量に関しては十分量が集まっているようです。
しかし、データの比率が514:6261とかなり偏っていることがわかります。
そのため精度を上げるためにはこの部分のデータを集めるか、予測範囲を狭める当を行うことで精度の向上が計れるかと思います。
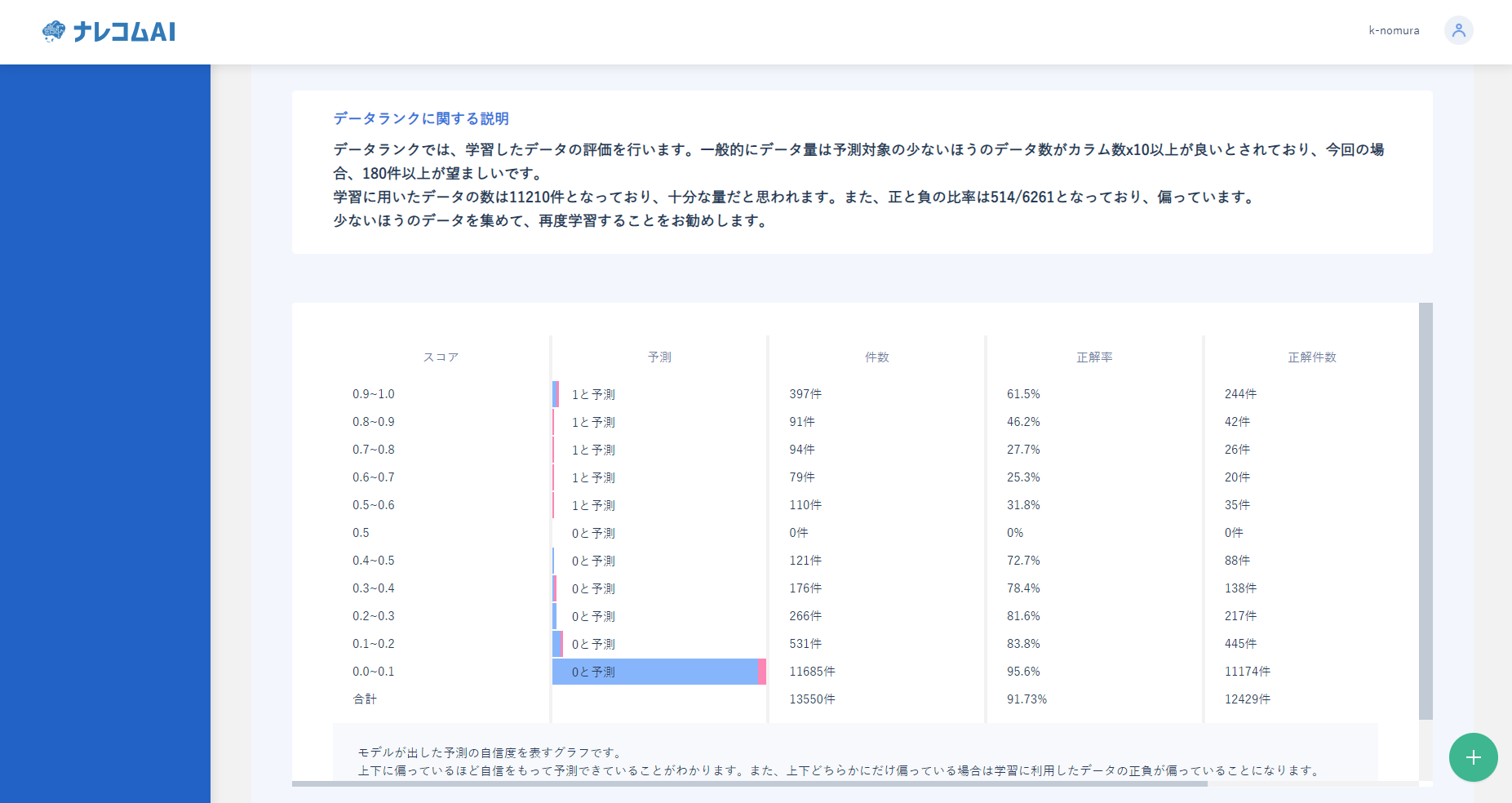 |
ナレコムAIで予測してみる
実際にナレコムAIで予測してみましょう。
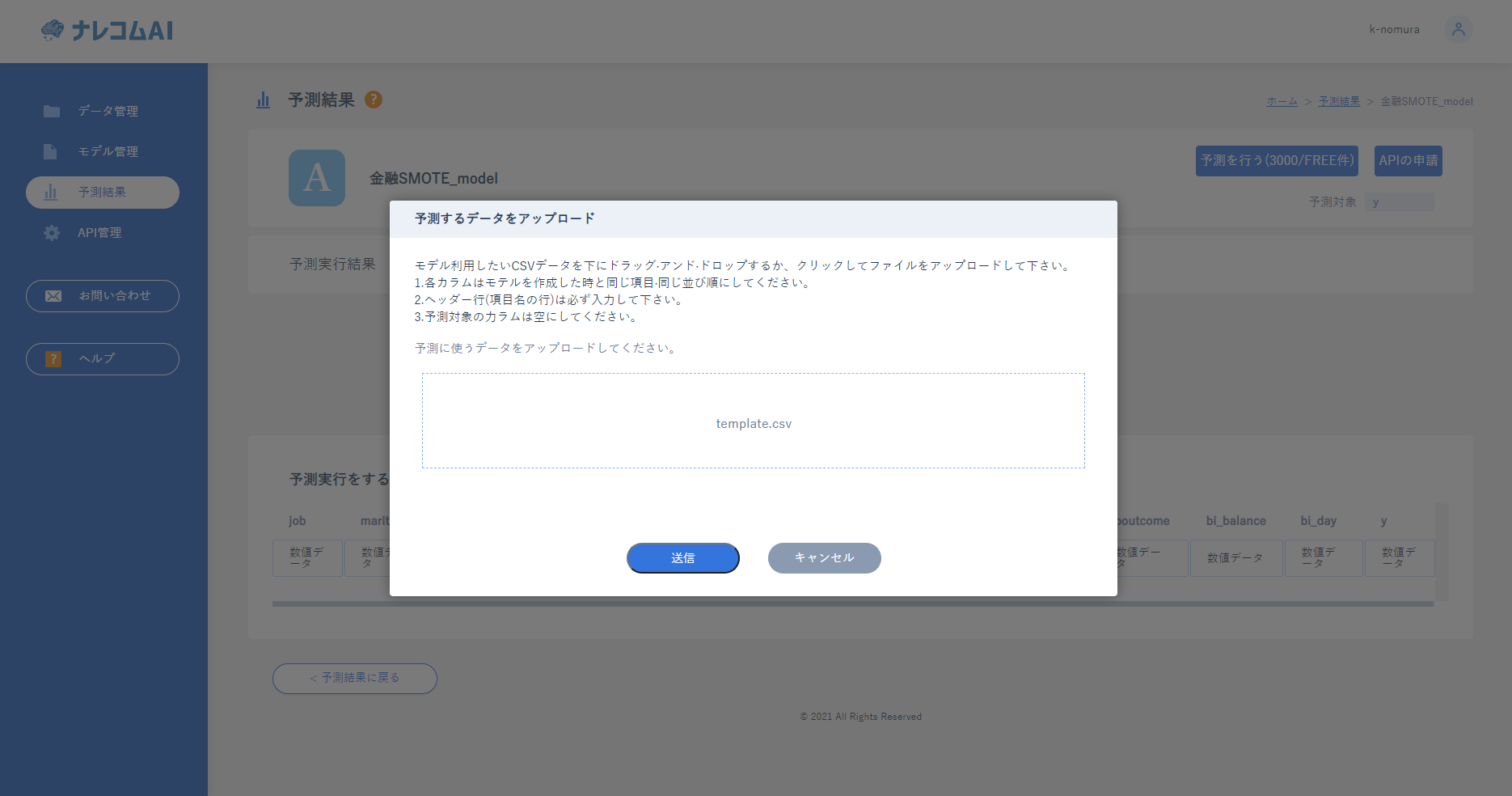
モデルの評価画面の右上の「このモデルを使用する」をクリックして右上の「予測を行う」をクリックしてください。
予測用のデータをアップロードし、送信をします。これだけで予測を行うことができます!
数分すると、ステイタスに結果のダウンロードと出てくるのでダウンロードして結果を確認してみましょう。もしくは
 |
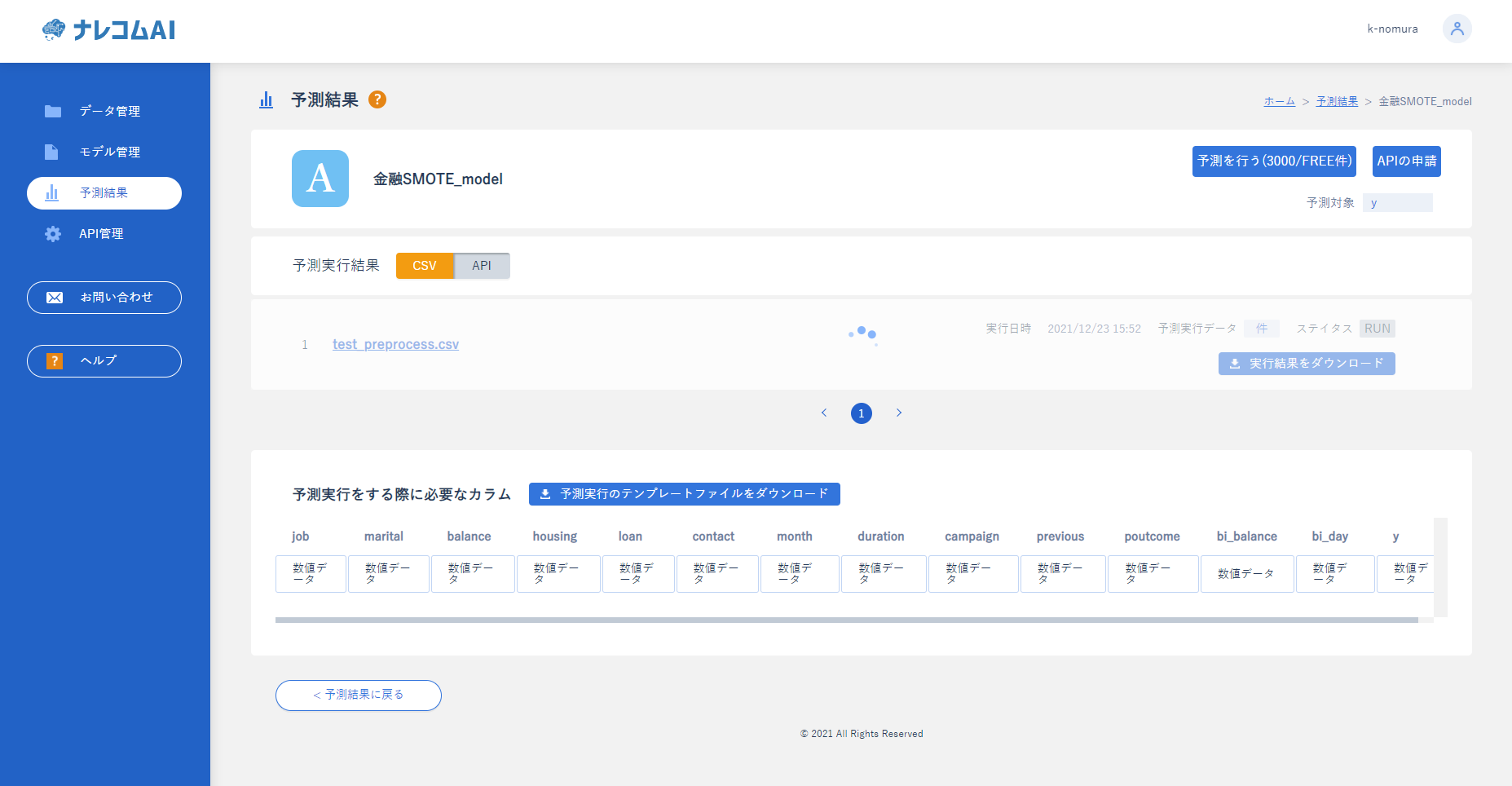 |
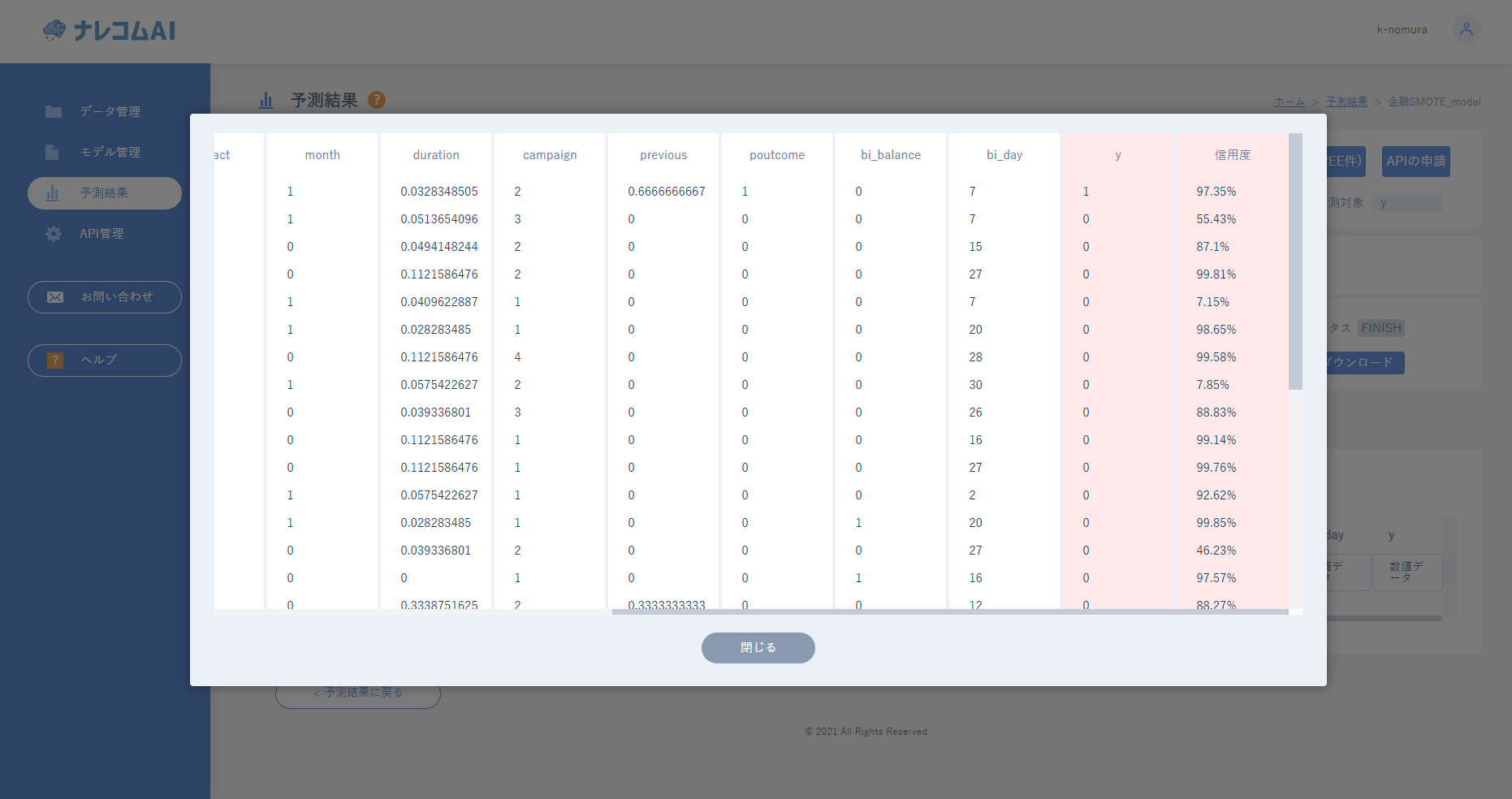 |
SIGANTEで結果を確認する。
先程ダウンロードした結果をSIGNATEに投稿して精度を見ていきましょう。SIGNATEにアップロードするようにデータを整えて、アップロードします。結果は0.8061482でした。データの前処理を行わずに0.8を超えているのはすごいと思います。
 |
まとめ
今回はキャンペーンに反応するかを予測するモデルを作ってみました。
データさえあれば、ナレコムAIを使ってすぐにモデルを作成することができ、SIGNATEのスコアでは良い結果を出すことができました。また、詳細を見てデータを消したり、前処理の内容を決めることができました。
余談
今回のレポートでデータのバランスが悪い点やデータの内容に文字列が散見されました。
データの一部にOneHotエンコードを行い、データのバランスをSMOTEという手法を用いてアプローチして再度モデル作成を行ってみました。
OneHotエンコードとは、データの出現を0/1で表現したデータに変更するものになります。
カラム数が増えるという欠点があるため、乱用するのは避けるべきですが、これにより予測対象と関係性があらわになることもあります。
SMOTEというのは、少ない方のデータをかさましし、多い方のデータを削減することでバランスを整える手法です。
今回は少ない方のデータも300件ほどとある程度の量があったため、こちらの手法をとりました。
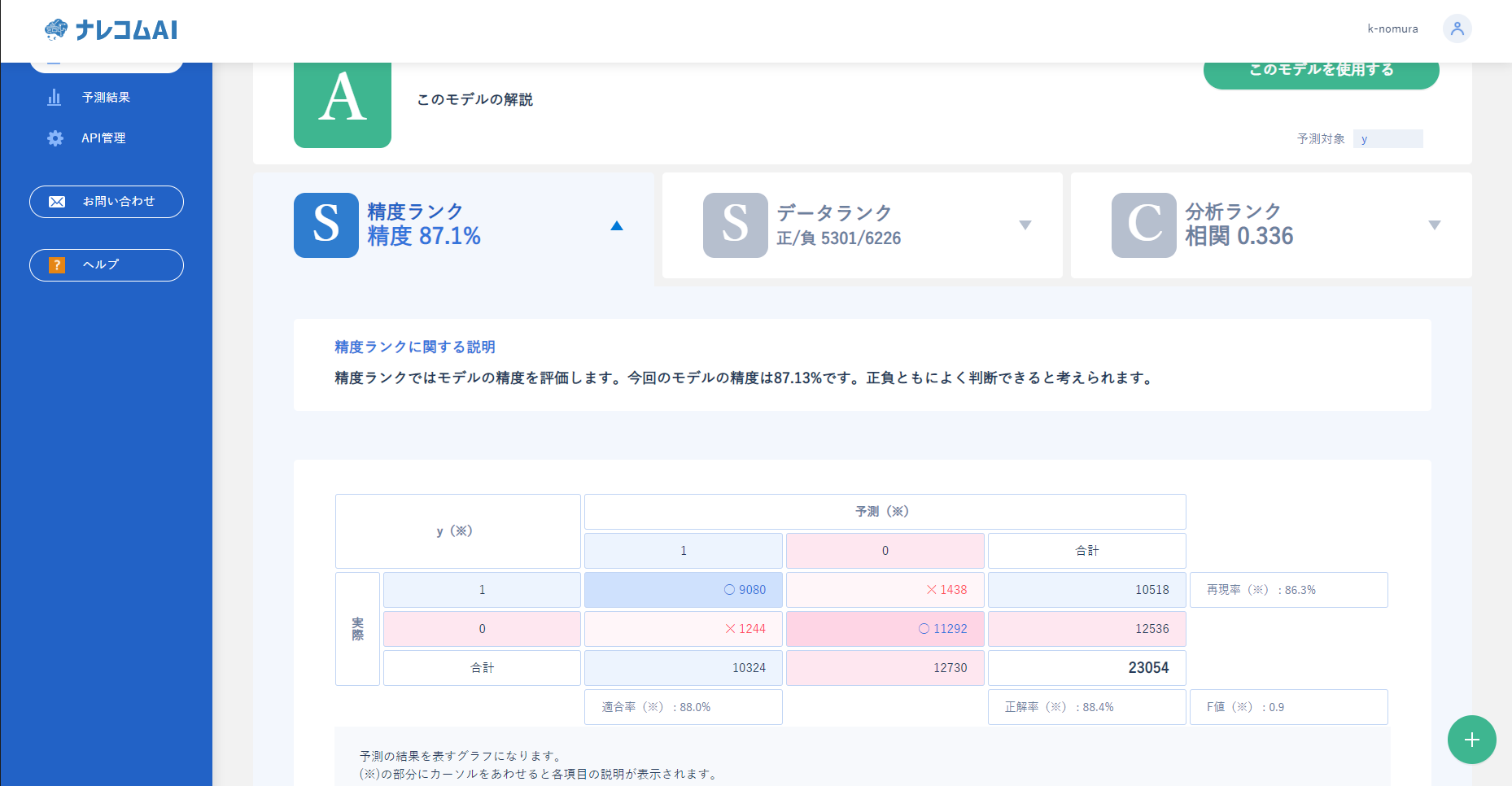
結果が以下のようになっており、精度ランクが良くなったことがわかります。
また、データランクをみてもスコアが上下に偏っており、自信をもって判断できていることがわかります。
 |
 |