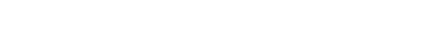
AutoMLツールナレコムAIでは、モデルの作成後レポートを確認することができ、モデルの特性をつかんだりより良いモデルを作るための参考にすることができます。今回の記事では回帰分析モデルのレポートの読み方を実際の画面を交えて解説します。
レポートの種類
ナレコムAIには「精度」「データ」「分析」の3つの指標に分けて評価を行っています。
| ランク名 | 利用用途 |
|---|---|
| 精度 | 予測精度の確認、運用の判断 |
| データ | 学習に利用したデータの評価 |
| 分析 | より良いモデルにするための確認 |
今回利用するデータについて
今回利用するデータはKaggleの住宅価格予測のデータを利用します。
精度ランクの読み方
それでは精度ランクを確認していきましょう。

評価の文章を読んでみると、精度は83%となっており高い数値が出ています。
続いてグラフを読み取っていきましょう。
まず散布図を見てみましょう。
散布図ではどの程度正確に予測ができているのかを可視化しているグラフです。
図の中の対角線に点が集まっているほど精度よく予測できていることがわかります。
今回の例だと値が低い部分はおおよそ正確に予測できていますが、400000を超えたあたりからばらついているようです。
この結果から、このモデルを運用する際は低い値は信頼でき、大きい値が出た場合はあまり信頼できない可能性があることが読み取れます。
続いて円グラフを確認してみましょう。
円グラフでは誤差の範囲ごとにデータの量を図って可視化したグラフです。
誤差の小さいデータが多いほど精度よく予測できることがわかります。今回のデータだと誤差が15%以下のでーたが6割ほどを占めているため精度よく予測できることが読み取れます。
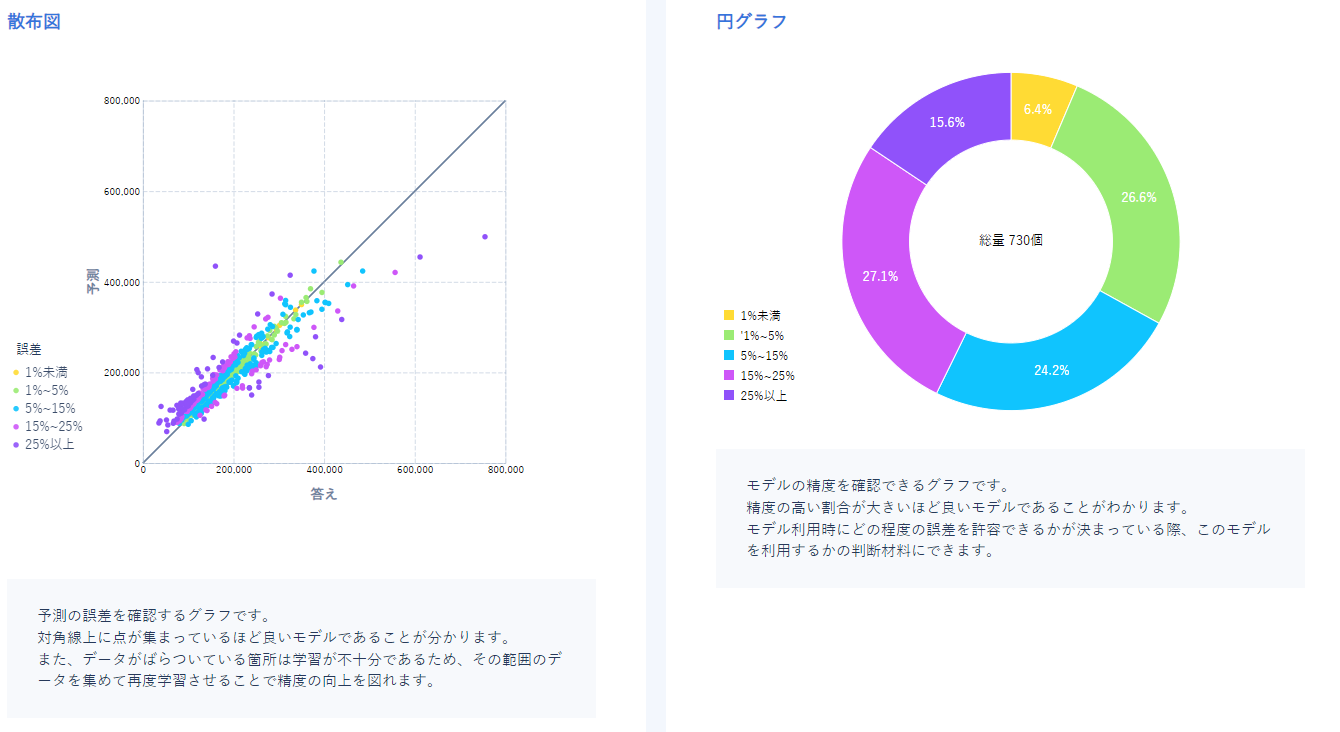
次に誤差率数量グラフについてです。
こちらは全体を通して誤差がどの程度出るのかを可視化したグラフです。
今回の誤差は平均12%ほどと出ているので、利用時にはこの誤差が出ることを考慮するとよいことがわかります。
この山なりのグラフは誤差の大きさと数量を表しており、今回のモデルは左に大きい山があるためよいモデルです。
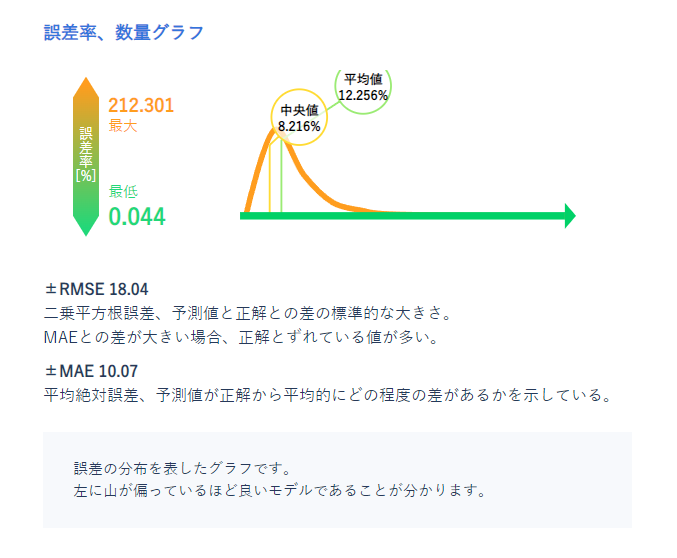
値の範囲とその誤差の数量では予測範囲ごとにどの程度の精度があるかを確認できます。
データの量が多い左側では精度よく予測ができているようですが、データの少ない右側は予測が不安定です。
データの少ない箇所を除いて一部でモデルを作成して運用するか、データを収集しなおすことでより精度の高いモデルを作成できるかもしれないことが読み取れます。
データランク
続いてデータランクを確認してみましょう。

データランクの文章を読んでみるとデータ量が足りていないことが読み取れました。
前処理によってデータ件数を増やしたり、利用する項目を減らすなどすることでデータの質を上げるべきであることが読み取れます。
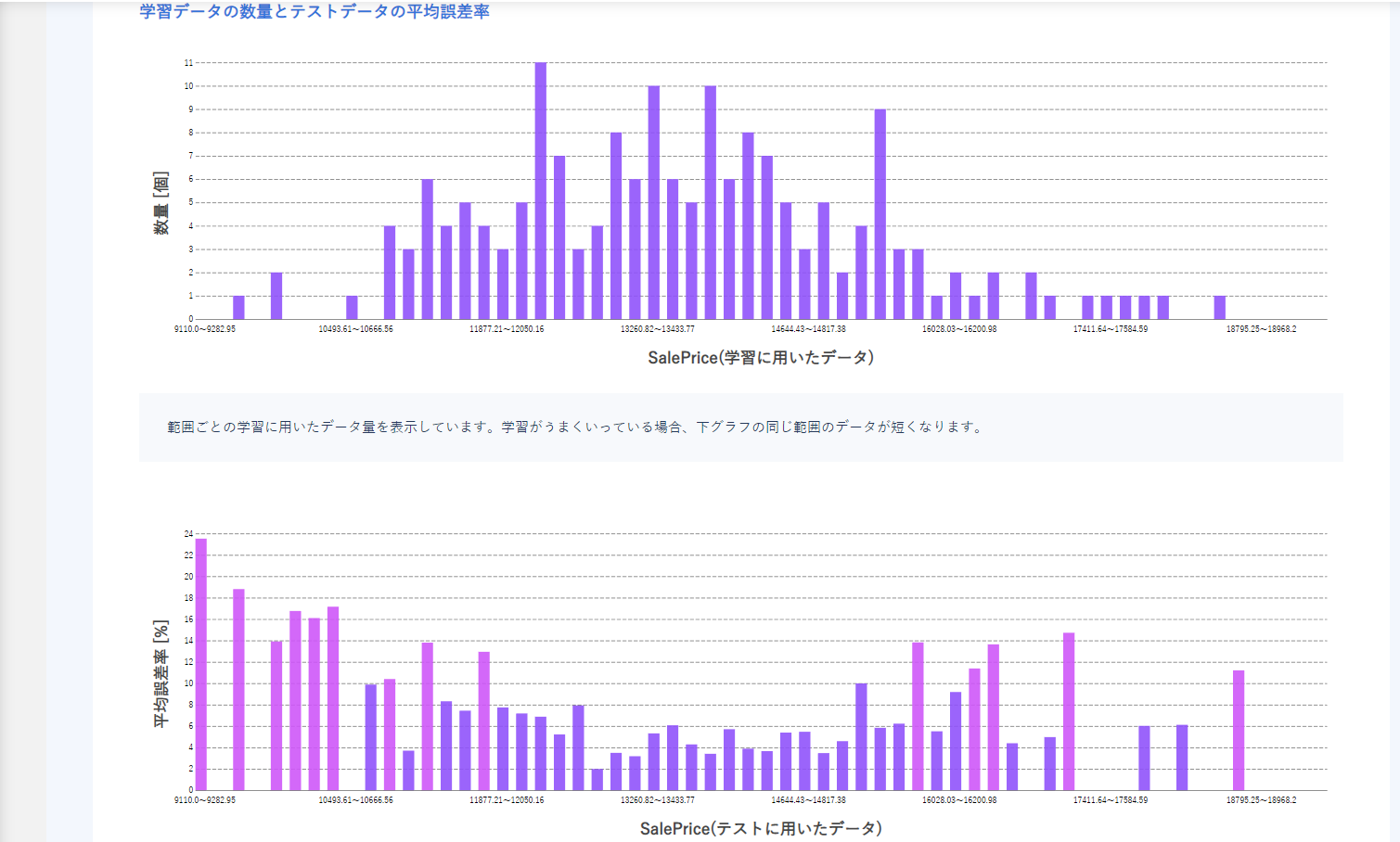
学習データの数量とテストデータの平均誤差率を見ることで範囲ごとに学習が十分できているかを確認できます。
多くの場合は上のグラフでデータが集まっている個所は十分学習ができており、その裏付けとして下の誤差率が少なくなっていることが多いです。
データが集まっていなかったり、学習が十分できていない箇所は学習範囲から除外したり、データを収集するなどして補完するべきであることがわかります。
分析ランク
最後に分析ランクを確認してみます。
文章を確認してみると高い相関を持つデータがありよいデータであることがわかりました。
また、特定のカラムに対して前処理したほうがいいことがわかります。

次に相関を確認してみましょう。
青いデータは強い相関を表しており、そのデータが複数あることがわかります。
もし学習データの取捨選択を行う場合はこの相関の高いデータは残したほうがいいかもしれません。
また、相関の高すぎるデータは予測時にはわかっていないデータの場合があります。
その場合運用することができないため、あらかじめデータを見直すことが大切です。

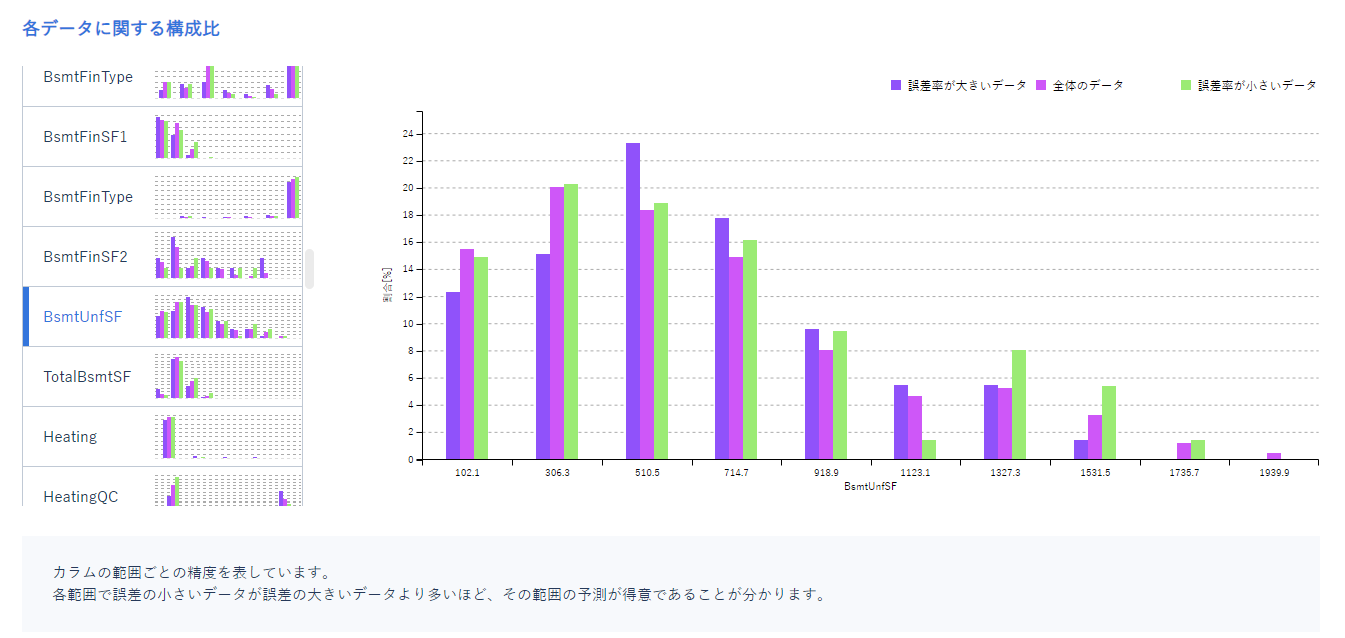
続いて構成比グラフです。
このグラフは誤差の大小とデータ全体の3項目をデータごとにまとめたものです。
特定の項目において、どの値のとき誤差が小さくなるのか等がわかることで精度の高さに影響しているのかを知ることができます。
これにより、誤差の大きいデータの箇所は学習が十分でない可能性があるので重点的に収集したり、学習から取り除くなどの前処理をする参考にできます。
まとめ
以上で回帰分析のレポートの解説を終了します。
次回は二項分類のレポートの読み取りについて解説するので、ご確認ください。