こんにちは、インターン生の須藤、年代、藤森です。
今回私たちはインターンシップとして8月21日から8月25日まで株式会社ナレッジコミュニケーション千葉オフィスにてデータサイエンティスト体験を行い、オープンデータからナレコムAIを利用した電力需要予測を実施いたしました。ナレコムAIにcsv形式のファイルを投入するだけで、簡単にモデル予測が作成できました。
ナレコムAIとは
ナレコムAIは、機械学習プラットフォームです。
インターンを通してナレコムAIを利用した感想としてこのナレコムAIには2点の大きな特徴があり、簡単かつ手軽に機械学習が利用できるサービスであると感じました。
1.機械学習のモデル作成を専門家なしで行える。
通常、機械学習を行う時は、モデル作成や評価といった仕事はデータサイエンティストという専門家が行います。しかし、ナレコムAIがあれば専門家なしで、モデル作成や評価といった仕事を簡単にすることができます。
2. 低い予算で利用を始められる。
機械学習を行うには、ソフトウェアライセンスの取得やハードウェアの購入など、一般的に数百万円の投資が必要と言われています。しかし、ナレコムAIではナレコムAIを使った分だけ支払いをすればいいので、5万円程から機械学習を利用することができます。また、専門家がいらないので人件費を抑えられ、更に低予算で機械学習を行えます。
今回の取組について
・データ分析に対するインターン実施前のイメージ
データ分析は楽しそうだったのですが、データ分析をする上で、データをどのようにして選別し、どのように分析したらいいのかわからず、想像よりも難しいものだと感じました。
今回はナレコムAIへ以下のデータの投入を行い電力需要予測を行うモデル作成を行いました。
・今回使用したデータ
csv形式のデータファイルを関西電力と気象庁のオープンデータからダウンロードしました。以下が使用したデータの種類です。
| 関西電力の電力実績 | 関西電力のピーク時供給力 |
| 祝日 | 前日の電力実績 |
| 日付 | 日照時間 |
| 予想最低気温 | 予想最高気温 |
| 実績最低気温 | 実績最高気温 |
| 平均気温 | 現地気圧 |
| 海面気圧 | 合計降水量 |
| 最大1時間降水量 | 最大10分間降水量 |
| 平均湿度 | 最小湿度 |
| 平均風速 | 最大風速 |
| 最大瞬間時風速 | 最大瞬間時風向 |
データ加工
私たちは、最初に使用したデータの中でどのデータが重要か探るために、2種類のcsvデータを作成しました。
データ1:日付(2011/1/1の様な形式)、時間帯、前日電力実績のデータを含むcsvデータ
データ2:1のデータから、日付を年/月/日のデータに分割し、使用データを全て加えたcsvデータ
この2つのcsvデータをナレコムAIに投入して、作成された予測モデルを見ていきます。
予測結果
データ1とデータ2の予測モデル下に示します。
結果よりどちらが良いモデルか比較します。
・決定係数について
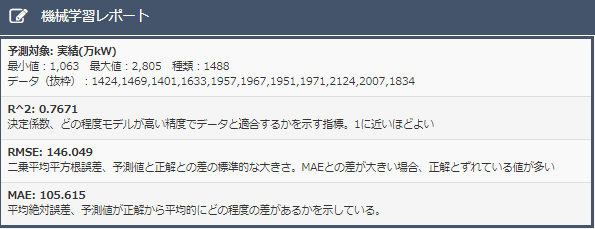
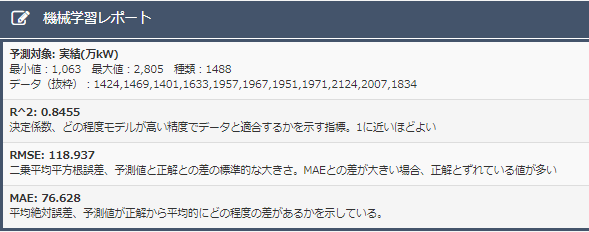
データ1の決定係数は0.761、データ2の決定係数が0.8455でした。決定係数は1に近いほど良い予測モデルなので、データ2の方が良い予測モデルであることがわかります。
・散布図について
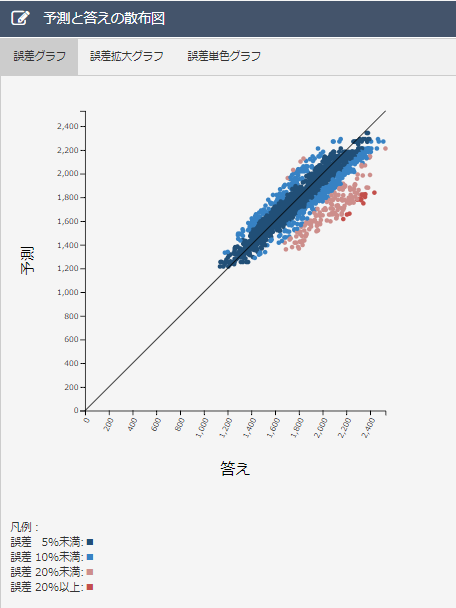
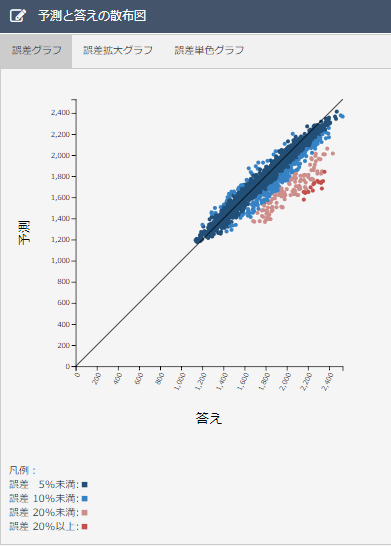
データ1、2を比べるとデータ2のほうが誤差10%以上のデータが少ないことがわかります。誤差20%以上のデータがデータ2の方が多いのは、電力需要予測には関係のないデータが紛れこみ、予測に悪影響を及ぼしているからだと考えられます。
・分布図について
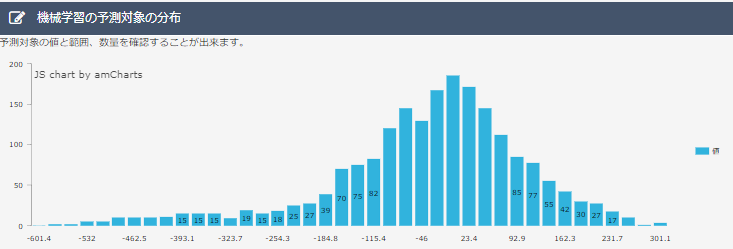
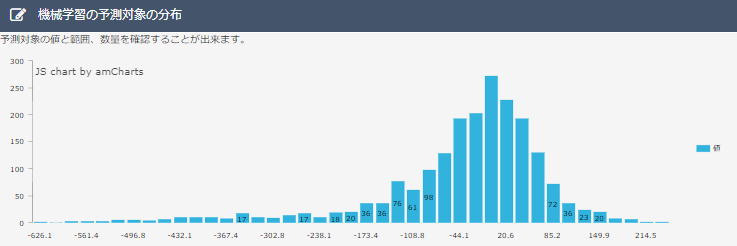 データ1、2を比べると、データ2のほうが誤差0%に分布するデータの割合が多くなっています。一般的に分布図がとがった山の形になるほど良い予測モデルであると言われているので、2のほうが予測モデルとして優秀なものといえます。
データ1、2を比べると、データ2のほうが誤差0%に分布するデータの割合が多くなっています。一般的に分布図がとがった山の形になるほど良い予測モデルであると言われているので、2のほうが予測モデルとして優秀なものといえます。
以上の比較より1より2のほうが優秀なモデルであるといえます。
次に2の予測モデルの精度を上げるために、相関係数ランキングを参考にして、不要なデータを以下の2種類の基準で予測し、削除しました。
基準1:上位10%相関係数ランキングでは下位のデータ、また、下位10%相関係数ランキングでは上位のデータを削除。
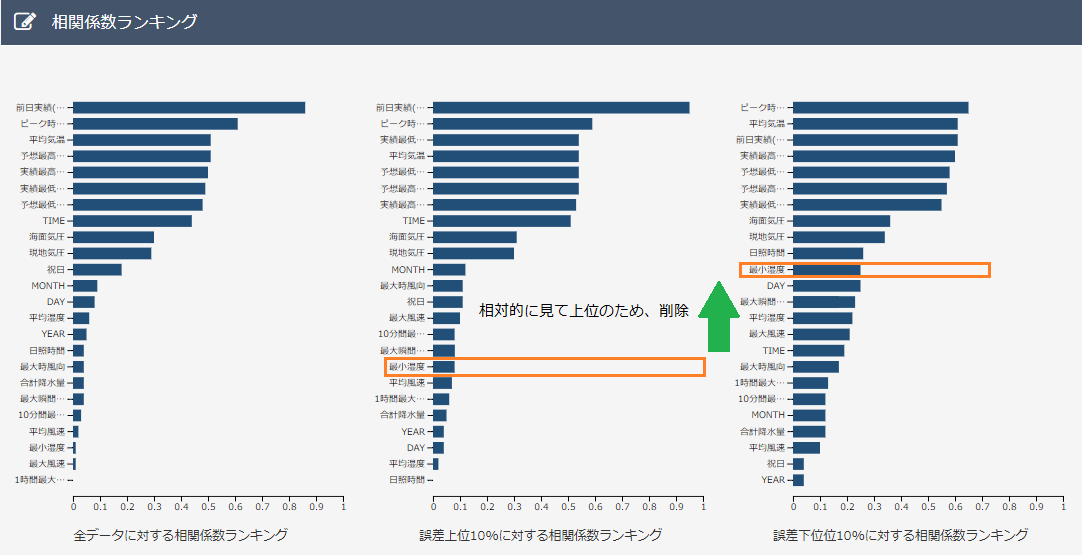
基準2.:上位10%相関係数ランキングにて相関係数が0.1未満のものを削除。
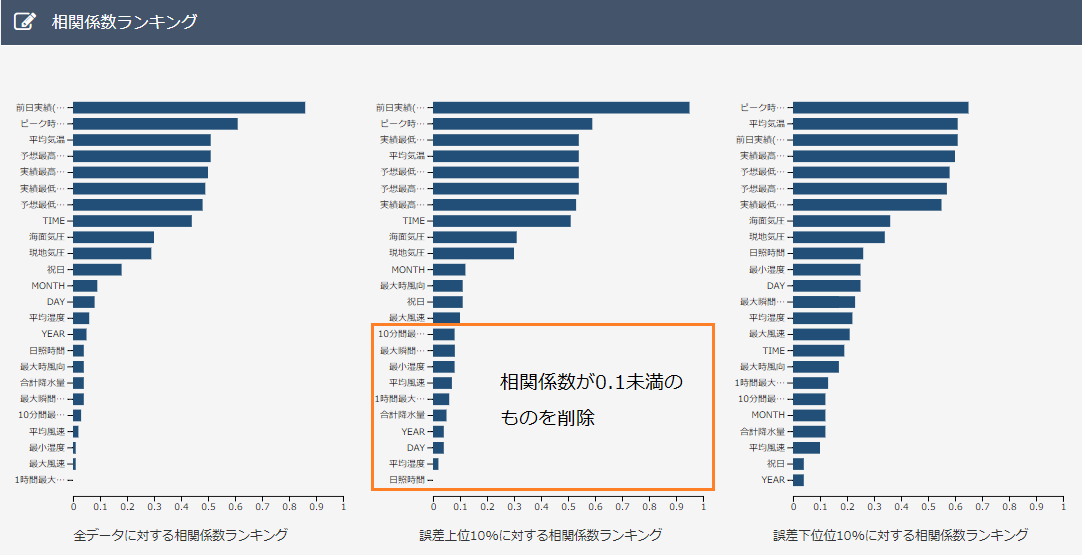
まず、基準1を適用して得られた予測モデルを次のようになりました。
・決定係数について
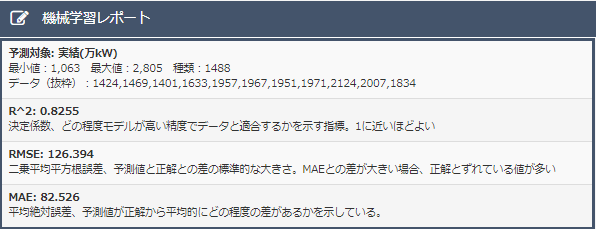
データ削除前に比べ、決定係数は減少してしまっている。
・散布図について
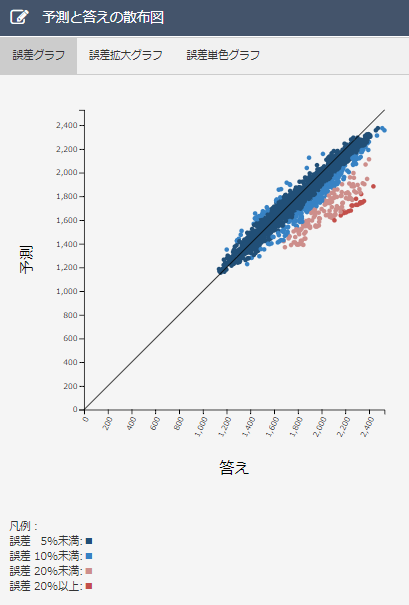
データ削除前に比べ、誤差10%以上のデータが増えてしまっている。
・分布図について
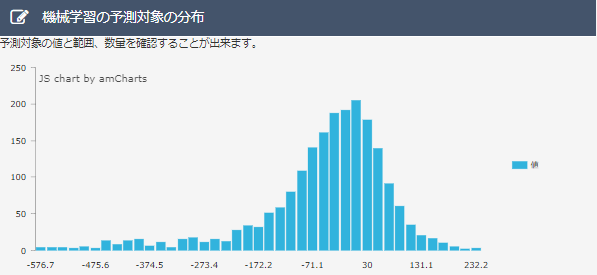
データ削除前に比べ、大きな誤差の分布が増え、誤差の少ないデータの分布が少なくなってしまっている。
以上より、基準1でデータを削除した場合、予測モデルの精度は下がってしまいます。
次に、基準2を適用して得られた予測モデルは次のようになりました。
・決定係数について
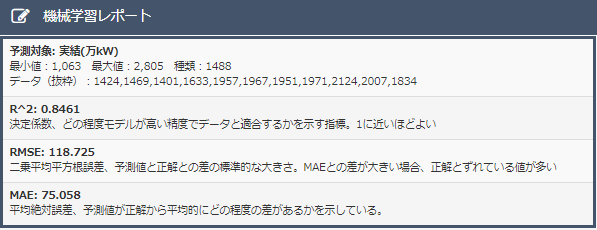
データ削除前に比べ、決定係数が大きくなり精度が上がっている。
・散布図について
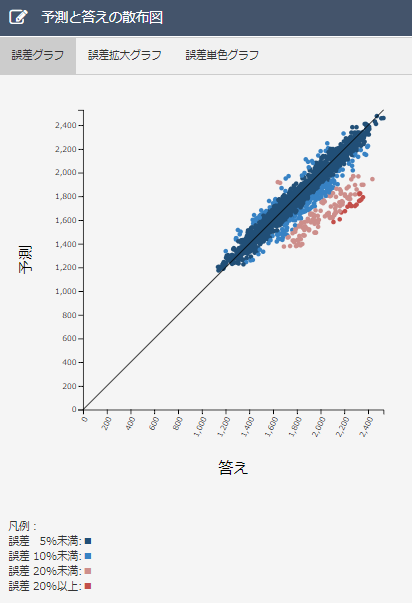
データ削除前に比べて、ほとんど変化がないため、優秀な予測モデルを保っていると言えます。
・分布図について
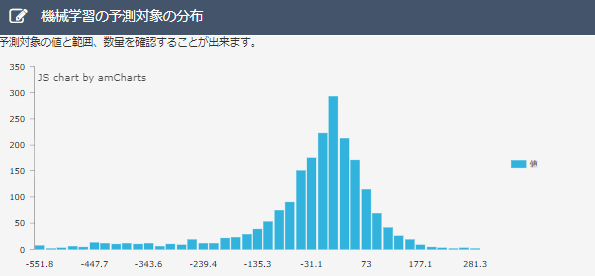
散布図と同様に、データ削除前と比べてほとんど変化がないため、優秀な予測モデルを保っていると言えます。
以上より、基準2でデータを削除した場合、予測モデルは優秀になることがわかりました。
更に予測モデルの精度を上げるために基準2をデータに適用し続けました。もし基準2が適用できなくなった場合は、上位10%相関係数ランキングにて一番ランキングが低いものを削除しました。そして次の結果が得られました。
・決定係数について
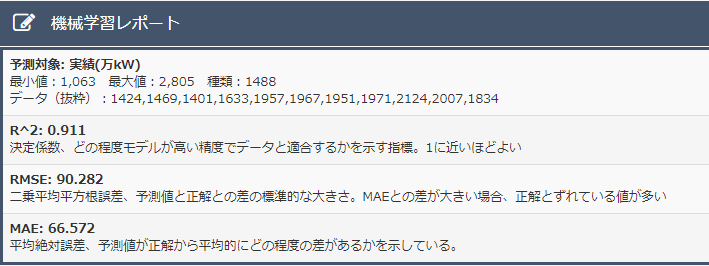
決定係数は0.911となり、非常に高い値が確認できました。
・散布図について
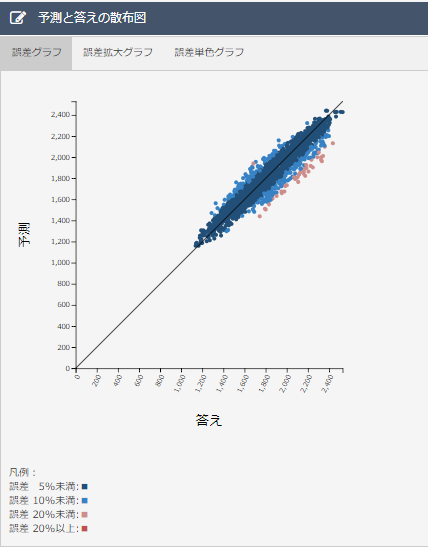
誤差10%以上のデータの数が明らかに減少しています。誤差20%以上のデータの数は0個になり、良い結果が得られました。
・分布図について
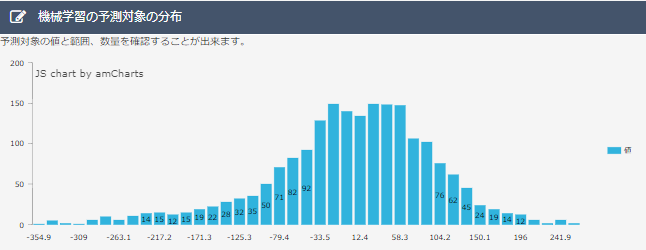
本来、とがった山のような形になるのが良いとされています。しかしこの分布図は台形のような形になっていて、良い結果ではありません。これはデータを減らしすぎた結果、過学習になってしまったと予想されます。
以上より、決定係数が高いだけでは精度の高い予測モデルであると言えないことが分かりました。また与えるデータが少なすぎると、精度の高い予測モデルは作れないということがわかりました。
よって、今回のデータサイエンティスト体験では、基準2によって初めに削除したデータが1番精度の高い予測モデルとなりました。
更に精度を上げられそうな仮説としては
・お盆やクリスマスなどの特別シーズンであるかどうかのデータの追加
・電力需要予測に関する論文を参考にしてデータの作成を行う
が考えられます。
インターンを通して
年代
最初は思うように精度が上がらず、いらいらする時間が続いていました。そもそもどうやったら精度が上がるのか。AIが分析した結果を自分たちが予測するのは難しいのではないかと思いました。しかし中盤になるにつれだんだん精度が良くなり、どんなデータ設計をすればよいかと考えるのが楽しくなりました。何よりも自分の推測の範疇を超えて出てくるデータの関係性に驚かされるのが楽しかったです。 今回インターンでは、機械学習の概要を学び、実際にデータサイエンティストを体験し、データ分析の大変さを学びました。それと共にAIの魅力を知り、充実した時間を過ごすことができました。これをきっかけにAIについてより深く学習していきたいです。ありがとうございました。
須藤
データ加工は初めての挑戦で、少しのデータの編集で機械学習の結果が変わってしまうことからデータ加工の重要さと、大変さが学べました。
ナレコムAIにデータを投入した結果、この予測モデルは良い結果なのか評価を出すことも難しかったです。
ナレコムAIを使えば約30分で予測モデルが作成されるので、データ加工という点のみに集中でき、とても良い体験となりました。
藤森
話題には上がるがよくわかっていないAIを自分で触れられるということで緊張と興奮がありました。
データ加工の際に元のデータを加工しAIに投入を行い、AIから出されたデータのデータをどのように加工したら精度にどのような変化が現れるのかを考えるのが難しいと感じました。特に相関係数ランキングや機械学習の予測散布図を分析したり、普段はあまり使わないExcelを用いてより良い精度になるようにデータ加工をしたりするのが難しいと感じました。
今回のインターンシップを通して機械学習の基礎的知識、データ加工の重要さと大変さ、初対面の人と考えながら1つの事を完成させる力、を身に着けることができ、とても良い体験になりました。
社員からのコメント
3人とも機械学習を扱うのは初めてながら高い成果を出してくれました。
機械学習を利用した学習モデル作成では、データの準備とできたモデルの評価が重要ですが、自分たちで考え、試行錯誤して今回のインターンに取り組んでもらい、思っていた以上の成果を出してくれました。ユーザ目線でのフィードバックももらい、今後のナレコムAIの機能追加と利便性向上に役立てていきたいと思います。
AIを仕事にしたい仲間を募集中です
ナレッジコミュニケーションでは、AIを始めとして、クラウドインテグレーション、VR、ロボットなどをやってみたい、という仲間を募集しています。
面接をご希望される方は、コーポレートサイトの採用情報のページをよりエントリをお願いします。応募をお待ちしております。